AI robustness for denied, degraded, intermittent, or limited (DDIL) environments

AI without the cloud
The emerging paradigm for AI software places a large language model (LLM) at the center of a web of computation. There are good reasons for this. The state of the art performance on nearly every benchmarked task is dominated by proprietary LLMs such as GPT-4 (OpenAI), Gemini (Google), and Claude (Anthropic), trailed closely by an ever-changing group of open source LLMs such as Llama-3 (Meta) and Mixtral (Mistral AI). Because these LLMs have "emergent" capabilities such as reasoning and coding, they can be used to perform tasks without any specific training. Software powered by LLMs are able to carry out new instructions, on never before seen data, without missing a beat.The problem is that LLMs live almost exclusively in the cloud. If the downrange users of LLM-powered software do not have high bandwidth access to cloud computing, then the state of the art LLMs go dark. And if there is no powerful local GPU cluster, even open source LLMs go dark.Most LLM-powered software has all-or-nothing functionality. So unless the users are on the free-flowing high-speed internet, LLM-powered software is useless.The least-served users of LLM-powered software operate in denied, degraded, intermittent, or limited (DDIL) communications environments. From SIGINT analysts on reconnaissance planes to special forces commanders in the field and engineers on submarines, LLMs are not reliably available. And as a consequence, very few AI solutions are being built for them today.DDIL users need AI tools just as much as—if not more than—the typical military user. To serve them, we need an alternative to all-or-nothing AI software. AI solutions for the DDIL environment must be designed for robustness.
Language models large and small
An engineered system is robust if it can handle degradation of resources without catastrophic failure. A classic technique for achieving robustness is redundancy. Pipelines of smaller language models (LMs) can bear much of the load when the resources that LLMs require become unreliable or unavailable.What counts as a "small" LM is a moving target, but operationally it is a model that can run — and run fast enough to be useful — on computing resources available in the DDIL environment. That could range from for example Dell's PowerEdge XR2 Industrial Rack Server in a TSI stack, down to a laptop like a Dell Precision 7780 with an NVIDIA GPU. With today's computer hardware that size threshold is 1 to 10 billion parameters for the model. (The largest open source LLMs are in the hundreds of billions of parameters range, requiring powerful clusters of specialized GPU clusters with massive memory capacity.) That means that BERT, open sourced by Google in 2018, and its many model ancestors such as the T5 series of models, are well within the limits. Also small enough are any of the slimmed-down open source LLMs taking advantage of efficiency tricks such as quantization.At a glance, small LMs have several advantages over LLMs:
- Small LMs are faster, often 10x or even 100x faster when network latency is included.
- Small LMs have more predictable and detectable failure modes than LLMs.
- Small LMs can be hosted on local infrastructure, even on laptops.
So why are small LMs used so rarely in the latest AI solutions? For one thing, size really does matter. Compared to LLMs, small models have challenges:
- Small LMs must be trained with task-specific data.
- When the real-world data changes, the performance of small LMs degrades and fresh training is required.
- No amount of training data can endow small LMs with the high-level reasoning capabilities of LLMs.
But there is another powerful force behind today's trend of building all-or-nothing LLM-powered solutions: Laziness.Engineering redundancy into AI software with small LMs requires much more work. The rinse-repeat cycle of labeling data, training models, and testing them requires months of careful data science. And that extra work must be repeated for every individual task that the AI solution performs. Most AI engineers prefer to hack together an 80% demo solution over a weekend using the OpenAI API and some prompt engineering.This is not to say that LLMs can be fully replaced by small LMs. There are some tasks that are simply beyond the capabilities of anything but the largest models: planning and executing complicated tasks based on unpredictable context, answering free-form questions based on multi-document text in low resource languages, helping a user through an open-ended chat-based interaction. Those tasks require an LLM.But if you look under the hood of almost any LLM-powered solution today, you will find that most of the work being done by an LLM can be handled by a smaller LM trained for the task: classification, entity recognition, summarization. Most of the work done by AI software does not require an LLM at all. In fact trained small models routinely outperform LLMs, even with few-shot prompts. And yet many, if not most, of the latest AI software calls on LLMs to do everything.Government customers of AI solutions are becoming wise to this emerging pattern. For one thing, all-or-nothing LLM-powered software becomes extremely expensive at scale, especially if it relies on proprietary LLMs in the cloud to perform every task. A tenth of a penny per minute per task per user adds up very fast.All-or-nothing LLM-powered software is also slow. If a simple classification task requires a 70 billion-parameter neural network to generate a blob of text—and the text is parsed and re-run when the model has instead helpfully mused about safety policy—you can be waiting 20 seconds rather than milliseconds.It should be obvious that DDIL environmental challenges aren't the only reason to build robust AI solutions. It makes for better, cheaper, faster software.Consider the use case of monitoring intercepted radio communications in the field for various threats. Running open source models locally easily beats a system relying on LLMs in the cloud. Ignoring the problem of network latency, a small trained FLAN-T5 model outperforms GPT-4 by as much as 20 f1 accuracy points on multiclass classification.
Robust model pipelines
So how do you achieve robustness without an army of data scientists? If you've read this far then I hope you don't mind diving deep into the details.At Primer we integrate smaller language models into our pipeline with a framework we built called BabyBear. The simple idea is to catch the data examples that don't require an LLM and handle them with smaller, faster, cheaper models. The models that power this triage are automatically trained by observing the most powerful model downstream, and periodically re-training to avoid data drift. It's automated data science.BabyBear can save so much time and money that we decided to open source it for everyone to use (paper, code). It was deeply satisfying to learn recently that the nonprofit group Engineers for Ukraine has been using BabyBear to minimize their software's latency and cost.To illustrate, here is an example of BabyBear in action on an OSINT task: Sentiment classification of tweets from politicians. The table below shows the performance of GPT-4 using a trained LM (RoBERTa, 335 million parameters) as the babybear model. Unsurprisingly, GPT-4 outperforms RoBERTa even without any specific training for the task. And as BabyBear's confidence threshold parameter is increased from 0.0 to 1.0, the work load shifts from RoBERTa to GPT-4 doing the work.But see where the performance of the system peaks. Rather than with GPT-4 handling every single inference, shunting 65% of the data examples to the small RoBERTa model results in about 5% gain in f1 score. So not only are we getting a modest bump in overall performance, we save most of the cost and latency of hitting the API for LLM inferences. And this also cuts the latency in half.
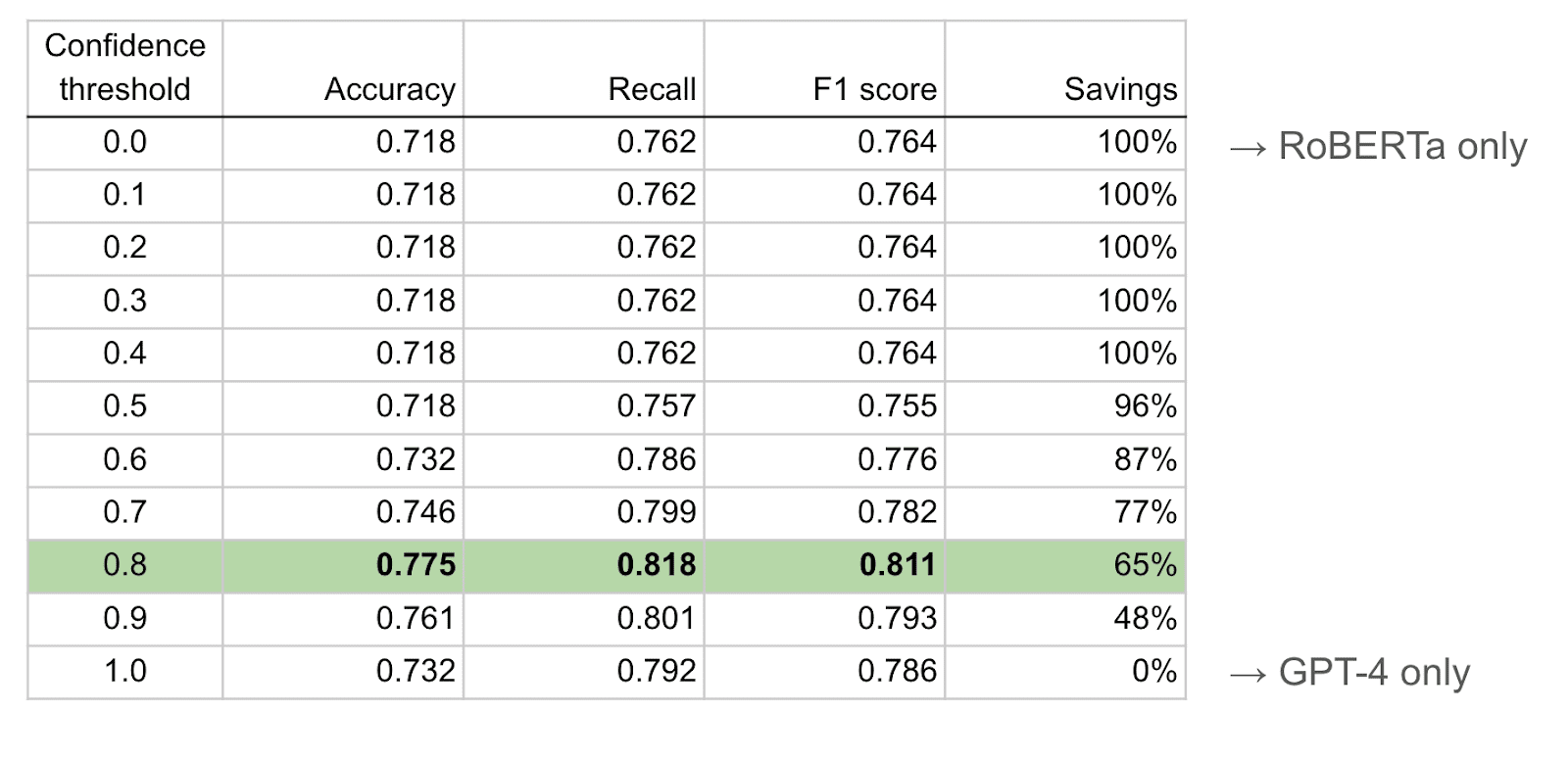
Note that this is open source training data, not ours.Like all open source benchmark data sets, the mix of classes has been made artificially balanced. Real-world data tends to be highly skewed toward true-negative examples. And the vast majority of those examples are not close to the decision boundary. They are easy examples that can be cleared away by smaller upstream models. Even a classical machine learning model such as XGBoost can often serve as the babybear model, achieving the savings with lightning speed on cheap CPUs.Ultimately, AI solutions need to adapt to the resources available - like all software, it should degrade gracefully in response to constraint. The DDIL environment is the most challenging. We should treat this as a rallying cry, rather than a problem to ignore. Building robust AI software for DDIL operators translates to better, faster AI for everyone.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



