TLDR: Re-imagining automatic text summarization
Too long, didn’t read.
When confronted with pages of long, hard-to-read text, we zone out and skip reading. Think back to the last book-worthy email your coworker sent out or that dense opinion article that your friend shared. These long texts are easy to ignore; in today’s internet-driven world, we want information without exertion.
But sometimes we want to know what a long document is saying. And sometimes, if you’re (un)lucky, you have to. Analysts across many industries need to read stacks of documents (news articles, government cables, law records), organize them mentally, and be able to re-communicate their findings.
Consider the following CNN article from 2016. It would be amazing if we could just read a perfect summary.
(CNN) — How did Amazon.com manage to build a tablet computer for less than the $199 price tag? According to analysts’ estimates, the company couldn’t. In order to meet the low asking price, Amazon will sell the Kindle Fire at a loss when it debuts on November 15, analysts said. The Internet’s largest retailer is apparently aiming to make up the costs by selling other goods, as it and other retail giants such as Wal-Mart Stores often do. Each Fire costs $209.63 to build, which includes paying for parts and manufacturing, according to technology research firm IHS iSuppli. That amount does not factor in research-and-development investments or marketing, executives for the firm have said. The preliminary estimate …
By algorithmically generating summaries of text documents, we could always enable readers to quickly learn the main ideas.
Building a human-level summarizer would require a foundational improvement in artificial intelligence. Our algorithms need to learn how to both understand a piece of text and produce its own natural language output. Both tasks are hard to achieve today: understanding text requires identifying entities, concepts, and relationships, as well as deciding which ones are important, and generating language requires converting the learned information into grammatical sentences.
Although these are lofty goals in AI, we have seen recent scientific developments start to close the gap between human and machine. Let’s take a look at the approaches to algorithmic summarization today.
Overview of summarization methods
For the past 10+ years, the most effective method for summarizing text was an algorithm called Lexrank. The algorithm pulls out individual sentences from a document, runs them through a mathematical scoring function that estimates how central each sentence is to the document, and selects a few of the highest-scoring sentences as the summary for the document.
LexRank belongs to the class of extractive methods, which use existing sentences from text to form the output summary. Extractive methods can utilize per-sentence features like word counts, sentence position, sentence length, or presence of proper nouns to score sentences. They can also use algorithms like hidden Markov models, integer linear programming, or neural networks to select optimal sets of sentences, sometimes in a supervised setting. While these methods produce safe and reasonable results, they are greatly restricted from expressing high-level ideas that span the whole text.
The most promising direction for summarization in the last two years has been deep learning-based sequence-to-sequence systems. These methods are abstractive, meaning they compose new phrases and sentences word-by-word, and they draw inspiration from the human process of summarization:
- Read a document and remember key content.
- Generate a shorter account of the content word-by-word.
The seq-to-seq systems have one component that reads in an input text and produces its own “representation” or “understanding” of the input, and one component that uses this representation to generate an abstractive summary. Notable papers developing these methods for summarization include those by Rush (2015), Nallapati (2016), See (2017), and Paulus (2017). We’ll now see how to intuitively derive and construct a seq-to-seq model for summarization.
Designing a seq-to-seq model
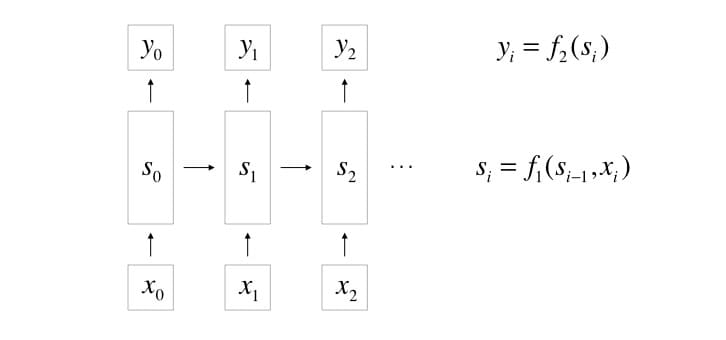
Deep learning uses neural networks to learn complex relationships. In our case, we need to elegantly handle arbitrary length inputs and outputs, which traditional feed-forward networks can’t easily do. So, we’ll want to use a particular deep learning construct called recurrent neural networks, or RNNs.
An RNN can learn patterns from sequential data by processing inputs one by one. It maintains an hidden state, or vector of real numbers, that represent what it has learned so far. At each step
ii
i, it uses its previous hidden state, denoted as
si−1s_{i – 1}
si−1, and the current input
xix_i
xi, to produce the new hidden state
sis_i
si. In that way, the state is a function of all previous inputs, and accumulates knowledge about all the inputs it has seen. Additionally, an RNN is able to generate an output
yiy_i
yi using its state
sis_i
si.
The variables
xi,six_i, s_i
xi,si, and
yiy_i
yi are typically vectors. In natural language processing, an RNN reads in words one-by-one in the form of word embeddings
xix_i
xi. Each word in an English vocabulary has its own embedding, or vector of numbers, that characterizes the word’s syntactic and semantic properties. By receiving a vector representation of each word instead of just the word itself, the RNN can better understand each input word. See this post for more detail about word embeddings.
Additionally, the functions
f1f_1
f1 and
f2f_2
f2 that produce the next state and output are usually neural network layers, hence the name recurrent neural network. In the following sections, we’ll denote (one-layer) neural networks as
y=f(Wx+b)y = f(Wx + b)
y=f(Wx+b), where
xx
x and
yy
y are the input and output,
ff
f is an activation function, and
WW
W and
bb
b are the linear parameters of the layer.
Building the model
So how can we use these building blocks to solve our problem? We can use one RNN to read in a document (the encoder), and one RNN to generate a summary (the decoder).
Encoder
The encoder reads the input document one word embedding at a time, producing a sequence of its own hidden state vectors. The RNN learns which “features” from the inputs are useful to keep track of. For instance, it could use one value in its state vector to track that the input is talking about tech gadgets instead of politics, and another to track whether the current input word is important. This corresponds to how a human might read and internalize a piece of text before beginning to formulate an output.
Note that the encoder could come across words that do not belong to its fixed vocabulary (e.g. a person’s name), in which case we feed it the embedding for the special unknown token “[UNK]”.
Decoder
We can then hand off the state vectors from the encoder to the decoder, whose job is to produce a coherent sequential output. When coming up with each word, a human might think back to which parts of the input were important enough to refer to again. So, we’ll also allow the decoder to decide which input words to focus on – that is, decide on an attention probability distribution over input words. The attention paid to each word
aia_i
ai is a function of the encoder’s state at the word
hih_i
hi and the decoder’s state
ss
s.
ei=vattnTtanh(Whhi+Wss+battn)e_i = v_{attn}^T \tanh (W_h h_i + W_s s + b_{attn})
ei=vattnTtanh(Whhi+Wss+battn)
a=softmax(e)a = \text{softmax} (e)
a=softmax(e)
In the example, the decoder is ready to say what product Amazon is releasing, and so concentrates on the word “Kindle”.
Now we are ready to generate the next word. The decoder can use its own state
ss
s and an attention-weighted average of the encoder’s states
h∗h^*
h∗, to identify top candidates for the next output word. In particular, the decoder outputs a probability distribution
Prgen\text{Pr}_{gen}
Prgen over its fixed vocabulary of words. From the distribution, we select the next word in the summary, and that word is fed back to the decoder as the input for the next time step.
h∗=∑iaihih^* = \sum_i a_i h_i
h∗=∑iaihi
Prgen=softmax(V2(V1[h∗,s]+b1)++b2)\text{Pr}_{gen} = \text{softmax} (V_2 (V_1[h^*, s] + b_1)^+ + b_2)
Prgen=softmax(V2(V1[h∗,s]+b1)++b2)
In our example, the decoder knows it is ready to output a noun (based on its hidden state) that is similar to “Kindle” (based on the weighted-average encoder’s state). Perhaps “tablet” is a good candidate word in its vocabulary.
This seems like a pretty intuitive yet potentially powerful algorithm! The model can use its own comprehension of the text to flexibly generate words and phrases in any order, including those that don’t appear in the original text. The steps of the algorithm are outlined in the code below.
encoder = RNN(encoder_hidden_dim)
encoder_states = []
# compute encoder states
for word in document:
encoder.process(word)
encoder_states.append(encoder.state)
decoder = RNN(decoder_hidden_dim)
summary = []
# generate one word per loop below
while True:
# compute attention distribution
attention_levels = [
v_attn.dot(
tanh(W_h.dot(encoder_state) + W_s.dot(decoder.state) + b_attn)
)
for encoder_state in encoder_states
]
# normalize the attention to make it a probability distribution
attention_levels = softmax(attention_levels)
# compute weighted-average encoder state
weighted_encoder_state = attention_levels.dot(encoder_states)
# generate output word
output_word_probs = softmax(
V_2.dot(
relu(V_1.dot(concat(decoder.state, weighted_encoder_state)) + b_1)
) + b_2
)
output_word = argmax(output_word_probs)
if output_word == STOP_TOKEN:
# finished generating the summary
break
summary.append(output_word)
# update decoder with generated word
decoder.process(output_word)
Training
Having defined how the model should work, we’ll need to learn useful parameters for the model based on training examples. These examples should contain (likely human-generated) gold-standard summaries of representative documents. In the domain of news articles, there is luckily a publicly available data set from CNN and Daily Mail of about 300,000 pairs of articles and human-generated summaries.
We train the model by showing it examples of articles, and teach it to generate the example summaries. In particular, we can sequentially feed to the decoder a summary word
wt∗w_t^*
wt∗ and ask it to increase the probability of observing the next summary word
wt+1∗w_{t + 1}^*
wt+1∗. That would give us the loss function
loss=−∑tlogPrgen(wt∗)\text{loss} = – \sum_t \log \text{Pr}_{gen} (w_t^*)
loss=−∑tlogPrgen(wt∗)
The promise of deep learning is that if we show the model enough examples, it will automatically figure out values for its (millions of) parameters that will produce intelligent results.
for article, summary in dataset:
model.train(article, summary)
Early results
A few thousand lines of actual Tensorflow code, an AWS p2 instance with GPU, and several days of training later, we can finally run:
model.evaluate(article)
on our previous example article. The output summary is:
Amazon will sell a tablet computer for less than
100million.Thecompanycouldmakeupforthelosseswithdigitalsalesorphysicalproducts.[UNK][UNK]:thecompanyislikelytolose100 million. The company could make up for the losses with digital sales or physical products. [UNK] [UNK]: the company is likely to lose100million.Thecompanycouldmakeupforthelosseswithdigitalsalesorphysicalproducts.[UNK][UNK]:thecompanyislikelytolose50 on each sale of the Fire.
That’s something! It’s impressive that the model learned to speak English and on-topic about Amazon, but it makes a few mistakes and produces some “unknown” tokens (“[UNK]”).
Improving reliability
While our above work is a great starting point, we need to make sure our results are more reliable.
Looking back at our generated synopsis, we notice that the model had trouble remembering the price of the tablet. In fact, that shouldn’t be surprising – after passing information through all the layers of networks, including the encoder, the attention mechanism, and the generation layer, it is really hard to pinpoint which number in the output vocabulary is closest to the correct one. In fact, we can’t actually report the real price of the tablets – the number ($199) is not even in our vocabulary! Similarly, the model replaces “Kindle” with “tablet computer” and the analyst “Gene Munster” with “UNK” because it isn’t able to produce those words.
Maybe we should allow our model to copy existing words in the input to produce in our output, just as a human may need to look to revisit an article to recall specific names or numbers. Such a pointer-copier mechanism See et al., 2017 would allow the model to shamelessly borrow useful phrases from the input, making it easier to preserve correct information (as well as more easily produce coherent phrases). The model can stitch together phrases from different sentences, substitute names for pronouns, replace a complicated phrase with a simpler one, or remove unnecessary interjections.
One simple way to allow for copying is to determine a probability
pcopyp_{copy}
pcopy of copying from the input at each step. If we decide to copy, we copy an input word with probability
Prcopy(w)\text{Pr}_{copy}(w)
Prcopy(w) proportional to its attention.
pcopy=σ(wh∗Th∗+wsTs+bcopy)p_{copy} = \sigma (w_{h^*}^T h^* + w_s^T s + b_{copy})
pcopy=σ(wh∗Th∗+wsTs+bcopy)
Prcopy(w)=∑iaiI[wi=w]\text{Pr}_{copy} (w) = \sum_i a_i I[w_i = w]
Prcopy(w)=∑iaiI[wi=w]
In the example, we might have a high probability of copying and be likely to copy “Kindle” since our attention is highly focused on that word.
Testing out this new model, we get the following summary:
Amazon will sell the Kindle Fire at a loss when it debuts on November 15. The internet ‘s largest retailer is aiming to make up the costs by selling other goods. Each Fire costs $209.63 to build, which includes paying for parts and manufacturing.
Brilliant – we can now reproduce specific facts from the article! The copy mechanism also helps with content selection, since we can more confidently express difficult ideas that we may have avoided earlier.
By reasoning through how humans think, we’ve essentially deduced a framework for the state-of-the-art methods in summarization.
Sample results
Our trained model can summarize news articles,
(CNN) — Inaccurate, inconvenient, ill-conceived … now add “potentially life-threatening” to the list of words being used to describe flaws in Apple’s much maligned maps app. Police in Mildura, Australia are warning drivers to be careful about using Apple Maps to find the city, which the app has placed more than 40 miles (70 kilometers) away in the Outback. Calling it a “potentially life-threatening issue,” police say the mapping system lists Mildura, a city of 30,000 people, as being in the middle of Murray-Sunset National Park. Several motorists have had to be rescued by police from the park, which police say has no water supply and where temperatures can reach a blistering 46 degrees Celsius (114 Fahrenheit). “Some of the motorists located by police have been stranded for up to 24 hours without food or water and have walked long distances through dangerous terrain to get phone reception,” Mildura police said in a statement. “Police have contacted Apple in relation to the issue and hope the matter is rectified promptly to ensure the safety of motorists travelling to Mildura…
Police in Mildura, Australia are warning drivers to be careful about using Apple Maps to find the city. The app has placed it more than 40 miles away in the Outback. Police have contacted Apple in relation to the issue and hope the matter is rectified promptly.
scientific paper abstracts,
The CRISPR (clustered regularly interspaced short palindromic repeat)-Cas9 (CRISPR-associated nuclease 9) system is a versatile tool for genome engineering that uses a guide RNA (gRNA) to target Cas9 to a specific sequence. This simple RNA-guided genome-editing technology has become a revolutionary tool in biology and has many innovative applications in different fields. In this review, we briefly introduce the Cas9-mediated genome-editing method, summarize the recent advances in CRISPR/Cas9 technology, and discuss their implications for plant research. To date, targeted gene knockout using the Cas9/gRNA system has been established in many plant species, and the targeting efficiency and capacity of Cas9 has been improved by optimizing its expression and that of its gRNA. The CRISPR/Cas9 system can also be used for sequence-specific mutagenesis/integration and transcriptional control of target genes. We also discuss…
We briefly introduce the Cas9-mediated genome-editing method, summarize the recent advances in CRISPR/Cas9 technology, and discuss their implications for plant research. The CRISPR/Cas9 system is a versatile tool for genome engineering that uses a guide RNA to target Cas9 to a specific sequence.
and even declassified government cables,
When political and economic storm clouds gather in Latin America, it is ineviakble that there will be talk of a military coup d’etat. El Salvador is no exception to this rule. Since president Romero assumed office on July 1, 1977, we have heard reports and rumors of unrest within the military establishment. some of this has obviously been the chronic grumbling of off-duty soldiers. Some has been attributed to hard-line senior officers supposedly dissatisfeid with president Romero’s moderation and failure to maintain “law and order”. And some has supposedly represented the thinking and dissatisfaction of younger officers dismayed by evidence of cooruption in high places and persuaded of the need for some political and economic structural reform. Sectors of the civilian population becoming aware of this real or reported coup d’etat sentiment react differently depending upon the inherent bias of each and its susceptibility to wish ful thinking…
We have heard reports and rumors of unrest within the military establishment in Latin America. Some of this has been attributed to hard-line senior officers supposedly dissatisfeid with president Romero’s moderation and failure to maintain “law and order”. Although the embassy has been cautious in attaching effective importance to this continuing volume of “coup talk”, we are now coming to the conclusion that more serious attention should be given it.
Interestingly, in the last example, the model copied the incorrectly-spelled word “dissatisfeid”. It must have decided that it was safer to reuse this unknown word rather than generate its own!
It’s also often useful to look at less successful examples:
A top European Union official said Saturday that new sanctions will be proposed within a week against Russia over its actions in Ukraine, but Ukrainian President Petro Poroshenko sounded like he can’t wait that long. “I think we are very close to the point of no return,” Poroshenko said Saturday following an EU summit in Brussels. “The point of no return is full-scale war, which already happened in the territory controlled by separatists and where — instead of separatists — there are regular Russian troops.” Poroshenko said the situation had worsened in the last few days and that thousands of foreign troops and hundreds of foreign tanks are now on Ukrainian territory. Russia has repeatedly denied either supporting the rebels or sending its own troops over the border. But those assertions have been roundly rejected by the West…
New sanctions will be proposed within a week against Russia over its actions in Ukraine. Russia has repeatedly denied either supporting the rebels or sending its own troops over the border. “I want to remind you that Russia is one of the most powerful nuclear Nations,” the President says.
In this summary, we get a quote from an unnamed president. While the model is able to substitute names when it identifies who is being referenced, it did not do so in this case. Another weakness of the model is that it often copies long phrases or even entire sentences from the source, having trouble coming up with its own wording. It turns out that true original language generation is really hard!
In this post, we’ve brainstormed how a good summarization algorithm should work. Stay tuned for our [next post]({{ site.baseurl }}{% post_url 2017-09-26-seq2seq %}) that will discuss the practical steps and challenges behind training a deep seq-to-seq summarizer.
Reference
Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. “Get to the Point: Summarization with Pointer-Generator Networks.” CoRR abs/1704.04368. http://arxiv.org/abs/1704.04368.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



