Solving Arabic Name Transliteration
What do Qassem Soleimani, Mohammed Bin Salman, and Abdel Fattah el-Sisi have in common?
If you have been following news in the Middle East and North African region, you probably guessed correctly. These are the names of highly influential figures in Middle Eastern geopolitics over the last several years.
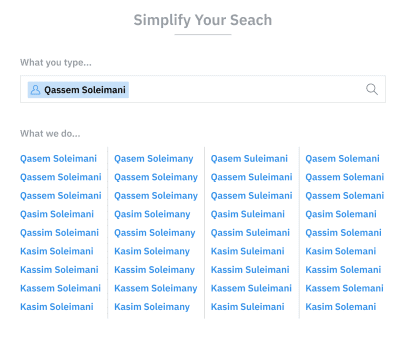
Another thing they share is that there are numerous transliterations for each name. For example, Qassem Soleimani can also be written as Qasim Soleimany or Qasem Suleimani or Kasem Suleimany, along with several other similar-sounding alternatives. Different spellings that share the same pronunciation are also known as homophones.
Variations among transliteration guides and ad-hoc decisions among content publishers result in multiple spellings for the same individual across a large corpus of text. If you are an analyst, you know this problem all too well. To run a simple search on a person of interest, you will find yourself writing complex boolean expressions like the ones shown below. Sample Query #1 shows some spelling variations you would write if you were running a search on the airstrike that led to the death of Qassem Soleimani. Meanwhile, in Sample Query #2, the search is for Egyptian President Abdel Fattah el-Sisi’s policy in the Sinai Peninsula.
Sample Query #1
("Qasem Soleimani" OR "Qasem Suleimani" OR "Qassem Soleimani" OR "Qassem Suleimani" OR "Qassim Soleimani" OR "Qassim Suleimani") AND ("death" OR "airstrike")
Sample Query #2
(“Abdel Fattah el-Sisi” OR “Abd el-Fattah el-Sisi” OR “Abdul Fattah el-Sisi” OR “Abd al-Fattah el-Sisi" OR "Abdel Fattah el-Sisy" OR "Abd el-Fattah el-Sisy" OR "Abdul Fattah el-Sisy" OR "Abd al-Fattah el-Sisy") AND ("Sinai Peninsula" OR "Sinai") AND "policy"
In the two queries above, we can see all the different spellings an analyst would have to manually generate about and then write out in a boolean expression to effectively capture the range of spellings for a given name. These booleans can become incredibly complex very quickly if an analyst wants to maximize the recall of their results and capture the full universe of potential spellings for a transliterated name. For example, we found the following spellings for the name Muhammad: Mohammad, Muhammad, Muhammed, Mohamed, Mohamad, Muhammad, Muhammed, Muhamed, Muhammed, Muhamet, Mukhammad, Maxamed, Mamadou, among others.
At Primer, we have built tools into our platform to do this heavy lifting for you. Our industry-leading Named Entity Recognition models can extract mentions of people in news articles and in your custom data sources.
To unburden analysts from the need to generate the universe of potential transliterations when searching for a person, we built a custom feature that generates name spelling variations for names that are transliterated from a language with Arabic script. Using a rule-based algorithm that synthesizes variants of a given name, Primer automatically resolves the alternate spellings to a single person from the span of documents you are searching over.
We created this rule-based approach with the help of a linguistics expert, who helped outline the universe of ways that a name could be transliterated from the Arabic alphabet to Latin script. For example, one rule that we use is substituting the letter “Q” at the beginning of a name with a “K”. Thus, when we encounter the name Qassem, we know that Kassem is a valid alternative. Another rule is the substitution of “ss” in the middle of a name with a single “s”. Again, using the example of Qassem, we end up with Qasem as an additional spelling.
If we use only the two example rules above, and recursively apply them to the name Qassem, we generate Qassem, Qasem, Kassem, and Kasem as valid alternate spellings. Our algorithm employs more than 25 similar rules, which helped us establish a library of potential spellings that our platform searches against when it encounters a name transliterated from Arabic script.
We also took additional measures to ensure that the generated variants do not contain false positives that could resolve a name that is shared across English and Arabic. For example, the name May (also spelled Mai) is common in Arab countries. We added additional checks to ensure that a substitution from May to Mai isn’t made when a name like Theresa May is detected in a search.
With our homophone detection feature, we programmatically generate spelling variants and use them to enhance the results of your queries. That way, you don’t have to worry about manually generating all possible spellings of a name (or dealing with complex wildcard operators), and instead focus on reviewing your analysis and gleaning key insights as quickly as possible.
So how does Primer’s transliteration technology perform?
We set up a test with three former intelligence analysts. Their task was to write Boolean queries to find all the mentions of Qassem Soleimani, Mohammed Bin Salman, and Abdel Fattah el-Sisi within an unclassified dataset. We timed how long it took them to create a Boolean query for each key person.
Here are the results:
Muhammad Bin Salman
Time to CompleteTotal DocumentsAnalyst 14:3012,452Analyst 21:3012,452Analyst 313:3010,149Average6:3011,684Primer Algorithm0:1012,696
Abdel Fattah el-Sisi
Time to CompleteTotal DocumentsAnalyst 15:002,527Analyst 21:5375Analyst 38:0070Average4:57890Primer Algorithm0:104,286
Qassem Soleimani
Time to CompleteTotal DocumentsAnalyst 115:0056,926Analyst 21:3421,679Analyst 34:0056,662Average6:5145,089Primer Algorithm0:1057,154
Primer was able to deliver 139% more results than the analysts on average across all queries and was able to reduce the average time to query from 6m 06s to < 10 seconds. If you’re searching for 15 people, that is over an hour of time savings to be gained. Imagine the time lost by a team of analysts running dozens of queries every day.

Extract from Primer Platform query on Qassem Soleimani, highlighting the different spellings of his name.
Analysts using this feature in Primer can now ensure that they are returning all the relevant results and that they are not missing any critical documents. The automation here will also save the analyst hours on a typical workflow.
If your organization can benefit from extracting information from textual data, we’d love to chat. To learn more about the solutions and features we’ve built with our natural language processing technologies, you can reach out to our team at info@primer.ai.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



