Here at Primer we are building machines that can read, write, and understand natural language text. We measure our progress by breaking that down into smaller cognitive tasks. Usually our progress is incremental. But sometimes we make a giant leap forward.
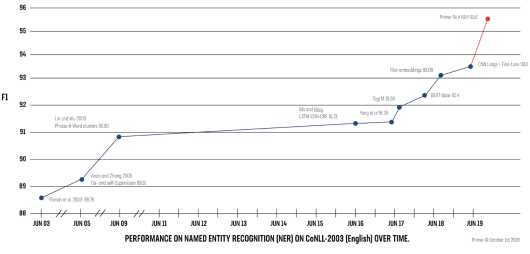
On the reading task of Named Entity Recognition (NER) we have now surpassed the best-performing models in the industry by a wide margin: with our model achieving a 95.6% F1 accuracy score on CoNLL. This puts us more than two points ahead of a recently published NER model from Facebook AI Research. More importantly, we are now on par with human-level performance. It requires consensus across a team of trained human labelers to reach higher accuracy.

Primer’s NER model has surpassed the previous state of the art models of Google and Facebook on F1 accuracy score. Graph adapted from Sebastian Ruder, DeepMind.
NER: What’s in a Name?
Named Entity Recognition (NER) is a foundational task in Natural Language Processing because so many downstream tasks depend on it. The goal of NER is to find all of the named people, places, and things within a text document and correctly classify them.
The gold standard benchmark for NER was laid out in a 2003 academic challenge called CoNLL. The CoNLL data set consists of news articles with all of the named entities hand-labeled by humans. (There is also a German-language CoNLL data set.) This established the four standard NER classes: person (PER), organization (ORG), location (LOC), and miscellaneous (MISC).
The NER labeling task is not as easy as it sounds. Consider this sentence:

After a thoughtful pause, a human reader can deduce that “Paris Hilton” is a person, “the Hilton” is an organization, and “Paris” is a location. (Humans will disagree about 15% of the time whether “the Hilton” should instead be classified as a location.)
A popular industry solution for extracting named entities from text is spaCy. Here is the output of spaCy 2.1 NER:

Not bad. The spaCy model does correctly identify all of the named entity spans. And it correctly identifies the second “Hilton” and second “Paris” as an organization and location, respectively. But Paris Hilton herself is misclassified as an ORG. So spaCy is only getting 66% accuracy on this text. And on our diverse gold-labeled NER data spaCy 2.1 falls well below 50% accuracy.
In order for models to be useful in a commercial setting, they need far better performance. So some new ideas are needed here.
New models are good, but data diversity is king
To create our own NER model we started with a BERT-based architecture and fine-tuned it for NER with the CoNLL training data. By switching to a universal language model like BERT, we immediately left spaCy in the dust, jumping an average 28 points of precision across all entity classes.
However, that higher precision came at a cost in recall. For example, Primer’s BERT-NER model was not confident enough to tag “Paris Hilton” in this sentence:

Pushing our NER model beyond state of the art required two more innovations. First, we switched to a more powerful universal language model: XLNet. But we discovered that even larger performance gains are possible through data engineering.
The CoNLL NER data set is limited to just one type of text document: Reuters news articles published in 1996 and 1997. This is very low data diversity compared to the internet-scale corpus of documents we process at Primer. We needed our NER model to be trained on a far broader range of writing styles, subject matter, and entities. So we curated a highly diverse group of gold-labeled documents, including entities from the financial, defense-related, and scientific worlds.
Injecting this diversity into our training data made all the difference. Even adversarial examples rarely stump Primer’s NER model:

Since the first universal language models like BERT came out one year ago, we’ve seen a revolution in the field of natural language processing. You can see this rapid progression in the graph above. But take note where Primer’s NER model lands. Our performance on CoNLL stands above the best results published by the enormous research teams at Google, Facebook, and the entire academic community. We have made more progress on NER over the past two months than the entire machine learning field has achieved in the past two years.

Primer’s NER model is approaching human-level performance. We find that individual humans disagree on consensus NER labels 15% of the time on average, even after training.
Of the four Entity groups, PERSON extraction has the highest performance with 0.94 precision and 0.95 recall. Location extraction is the second highest with organization third and Miscellaneous the fourth highest ranking. These results mirror the performance of our human evaluators against gold standard data, with humans having the lowest inter-annotator agreement on the miscellaneous and organization categories.
Putting NER to work
So what can you do with the world’s best NER model?
Primer powers analyst workflows in some of the largest organizations in the world. Better NER translates to better downstream natural language processing. It powers coreference resolution to correctly attribute every quote by every politician and CEO in the world. You need it for relation extraction to convert unstructured text that describes entities into structured data—facts about people, places, and organizations. And for text classification, for example identifying corporate risks hidden deep inside a company’s financial documents.
To see how NER works on a text document, consider this transcript of Mark Zuckerberg’s congressional testimony. It takes about 5 seconds to process the 50,000+ words with Primer’s NER model and extract 271 people, places, organizations, and even named entities such as Facebook’s Libra cryptocurrency project. (See the output below.)
For a deeper stress test we’ve been running it on document types that it has never seen before. For an extreme test we turned to Harry Potter fan fiction novels. Because if our model deduces that the Noble House of Potter is an organization, Phobos Malfoy is a person, Libere Loqui is a miscellaneous entity, and Snog Row is a location, then extracting the named entities from business documents should be a walk in the park.
So how does it do? We’re glad you asked. We ran the experiment and here are the results. Below is the output from Zuckerberg’s congressional grilling.
NER output from Mark Zuckerberg’s congressional testimony, 23 October 2019
People
| Cheryl | Tipton | Perlmutter |
| Vargus | Congressman | Casten |
| Martin | Clay | Mister |
| Mister Meeks | Cleaver | Barr |
| Hawley | Phillips | Inaudible |
| Warner | Davidson | Chan Zuckerberg |
| Vargas | Gonzalez | Mark Zuckerberg |
| Beatty | Riggleman | Bud |
| Chair Waters | Pressley | Axne |
| David | Zuckerman | |
| Luetkemeyer | Huizenga | |
| Mr Zuckerberg | Kostoff | |
| Emmer | Speaker | |
| Scott | Foster | |
| Hollingsworth | Ms. Waters | |
| Gonzales | Presley | |
| Himes | Gottheimer | |
| Green | Stivers | |
| Louis Brandeis | Loudermilk |
Organizations
| FinCEN | EU | Hamas |
| Senate | OCC | LGBTQ |
| Liberty | European | NCMEC |
| law | DNC | FDIC |
| AML/BSA | FHA | NFHA |
| fed | CFT | CFPB |
| HUD | ACLU | |
| PayPal | congress | BFSOC |
| SEC | Newsweek | Visa |
| Alipay | Congress | Dais |
| FTC | Calibra | Rand |
| FBI | Uber | |
| Stripe | NASDAQ | FINMA |
| YouTube | DOD | VISA |
| AML | BSA | Crypto |
| Lyft | ICE | |
| Subcommittee on Oversight and Investigations | eBay | Nazi |
| MDIs | CFTC | |
| Collibra | First | FHFA |
| UN | Super | LLCs |
| FINCEN | Black Lives Matter | Pew Research Center |
| Dias | The New York Times | Bookings Holdings |
| House | Fintech Task Force | The Washington Post |
| Ebay | Federal Reserve | Financial Stability Board |
| NAACP | US Treasury | The Department of Justice |
| US Department of Housing and Urban Development | Facebook Libra | Cambridge Analytica |
| G7 | Black Mirror | Financial Services Committee |
| MasterCard | Congresswoman | Hezbollah |
| Anchorage Trust | AI Task Force | Senate Intelligence Committee |
| Trump Hotel | Capitol Hill | Independent Libra Association |
| Muslim Advocates | Mercado Pago | National Fair Housing Alliance |
| The Capitol | Social Network | Office of Secretary of Defense |
| The Daily Caller | Trump Hotels | Microsoft |
| regulators | The Guardian | National Center on Missing and |
| LIBOR Association | New York Times | Securities Exchange Commission |
| Libra Association | Wells Fargo | Committee on Financial Services |
| Libra association | Congressmen | Independent Fact-Checking Network |
| Labor Association | US Congress | International Fact-Checking Network |
| Georgetown | European Union | |
| Congressional | United Nations | Supreme Court |
| Trump International Hotel | Department of justice | Messenger |
| Federal Reserve Board | Federal Housing Agency | The Times |
| WeChat Pay | Rainbow Push coalition | Independent Association |
| Georgetown University | Department of Justice | Federal Trade Commission |
| Housing Rights Initiative | terrorists |
Locations
| California | Americas | Venezuela |
| Iowa | Michigan | Asia |
| Pacific | Arkansas | North Korea |
| Washington | U.S. | North America |
| Myanmar | Oklahoma | Switzerland |
| Utah | America | Georgia |
| Indiana | New Jersey | Guam |
| Minnesota | Alaska | Germany |
| Washington DC | Pennsylvania | Florida |
| Illinois | Africa | Canada |
| U S | Silicon Valley | Cyprus |
| New York | Washington, DC | Russia |
| DC | Texas | Iran |
| US | Christchurch | France |
| Colorado | Syria | Ohio |
| Virginia | Connecticut | New Zealand |
| Tennessee | South Dakota | North Carolina |
| Missouri | Massachusetts | Turkey |
| United States of America | China | Europe |
| Kentucky | United States | Maryland |
| District | Qatar |
Miscellaneous
| The President | Colibra | XRP |
| American Nazi | Zuck Buck | African Americans |
| AI | Americans | Indian Muslims |
| Stump | Russian | Anti |
| Sarbanes-Oxley | American | Dune |
| Libra | Chinese | Libra Project |
| Green New Deal | Patriot Act | Iranian |
| Libra White Paper | Republicans | Future |
| Russians | Venezuelan | Democrats |
| Democratic | Hispanics |


