Machine Readers Judging Machine Writers

Automatic text summarization is one of the most challenging and most valuable commercial applications of natural language processing. Saving the typical business or intelligence analyst even just half an hour per day of unnecessary reading is worth billions of dollars.
Progress has been stalled by a bottleneck: We still rely on human data labelers to evaluate the quality of machine-generated summaries because automatic algorithms aren’t good enough. Human readers are just too slow and costly. If you can’t measure performance on a task—automatically, accurately, and at scale—then you can’t teach machine learning models to do that task.
What’s needed is a machine reader to evaluate the work of the machine writers.
Here at Primer, we’ve created a machine learning system that goes a long way towards breaking the bottleneck. We call it BLANC. It uses a deep learning language model to directly measure how helpful a summary is for understanding the target document.
You can read our research paper about BLANC on arXiv and find our open source implementation on GitHub.
The problem
When a machine writes a summary of a document for you, how do you know if it did a good job? You could read the document yourself and check, but the whole point of a summary is to save you that time.
You can evaluate the machine’s performance using a benchmark data set. The industry standard is a collection of 300k news articles published by CNN and the Daily Mail that include human-written summaries. You can test the machine on this data by applying one of the standard algorithms: BLEU and ROUGE. They score your machine-generated abstracts by measuring the text overlap with the human-written summaries. The more overlapping words and phrases between the summary and the original document, the higher the score.
This method is easy to implement, but it has two big problems. The first is that if a summary uses new words that are not in the original document, then it is penalized even if the summary is a masterpiece. Secondly, if the type of summary is different from the CNN/Daily Mail style of summary, then you’ll need to create a diverse set of human-written reference summaries of your own. This costs a lot of time and money to produce.
The more fundamental problem is that agorithms like BLEU and ROGUE judge summaries without even looking at the documents being summarized. This makes them so limited that you’re better off reading the texts and checking the summary quality yourself.
A solution
Ultimately, the goal of summarization is to help a reader understand a document by giving her the gist. So an ideal method for summary evaluation would simulate a human reader trying to understand the target document.
Our solution to this problem at Primer was to create BLANC. We named it as a Francophilic successor to BLEU and ROUGE.
BLANC simulates a human reader with BERT, a language model that was trained on a fill-in-the-blank game on the text of Wikipedia and digitized books. (Or as we call it, a fill-in-the-BLANC game.)
Out of the box, the BLANC method measures how well BERT guesses hidden words in the target document. Then it measures how much of a performance boost it gets from having access to the summary. In another version of BLANC, the performance boost comes from first fine-tuning BERT on the summary.
Unlike BLEU and ROUGE, BLANC requires no human-written reference summary. The document and summary go in, and the summary quality score comes out. BLANC makes it possible to use any domain or style of text from the underlying language model encountered in its original training.
How good is BLANC?
Can BLANC really judge a summary by its semantic content? Or is it just a fancier version of ROUGE that gives high marks to summaries that contain keywords or phrases from the document?
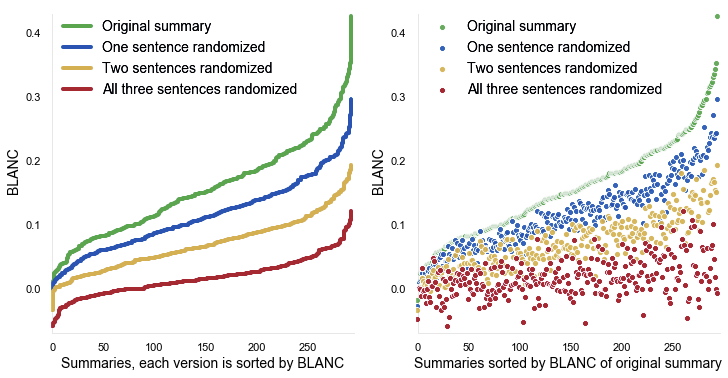
We tested the performance of BLANC by gradually corrupting summaries. Then we deliberately added noise by replacing more and more of the summary text with random words or sentences from the source document. The results shown in figure 6 of our paper are remarkable. For BLANC, the less meaning a summary has—even while retaining the vocabulary and turns of phrase of the document—the lower its BLANC score.
Consider this news document, which you don’t have time to read.
Here is a human-written reference summary:
Human-written summaryHorsemeat was found in a canned beef product sold at discount chains.Food watchdog says the sliced beef in rich gravy was made in Romania.It was found to contain between one and five per cent horsemeat.
ROUGE: 1.0
BLANC: 0.106
The reference summary has the maximum possible ROUGE score of 1.0, simply because ROUGE assumes that it is perfect. But is it? The summary gets a BLANC score of 0.106. This can be loosely interpreted as the summary “helping” BERT to understand the document 10% better than it would have without it.
Here are two different summaries for the same document:
Summary #1A tinned beef product in the UK has been withdrawn from sale.The Food Standards Agency (FSA) found Food Hall Sliced Beef in Rich Gravy to contain 1% to 5% horsemeat DNA.The FSA findings relate to one batch produced in January 2013.The tinned beef is sold in Home Bargains and Quality Save stores.ROUGE: 0.283
BLANC: 0.207Summary #2Beef found in canned horsemeat product sold at discount chains.Romania says sliced beef in rich gravy made in Watchdog.It was found to contain between one and five horse per tin.
ROUGE: 0.754
BLANC: 0.053
Summary #1 is clearly better than #2 by any reasonable standard. It is more informative than the original summary. It also makes none of the grave factual errors of summary #2. The BLANC score reflects this: Summary #1 is twice as helpful for understanding the document as the original human-written summary, and four times more helpful than summary #2.
Yet the ROUGE scores tell exactly the opposite story. Simply because summary #2 shares the vocabulary and turns of phrase of the human-written reference summary, its ROUGE score is more than twice higher.
Super-human reading and writing
Ultimately, we care how useful a summary is to human readers. To test how well correlated BLANC is with human evaluations, we worked with Odetta.ai. (We wholeheartedly recommend Odetta to the machine learning community; they are as much our data science partners as service providers.)
The Odetta team scored a diverse sample of news article summaries on multiple quality dimensions. The scores for the same summaries from BLANC put us right in the middle of that distribution: BLANC is a machine reader that judges the quality of summaries as well as a trained human annotator. (See figure 8 in our paper.)
This first version of BLANC takes a few seconds to judge the quality of a typical 800-word news document summary. It takes a human evaluator several minutes to do the same task. Then, it takes 5 to 10 minutes for a human to write the summary, which takes a second for a machine.
With further refinement, we expect BLANC to achieve superhuman skill at judging the quality of document summaries. That will help us train machine writers which, finally, will spare humans from having to read everything themselves.
You can read more about the implications of our research: Human-free Quality Estimation of Document Summaries.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



