Language Agnostic Multilingual Sentence Embedding Models for Semantic Search
Language Agnostic Multilingual Sentence Embedding Models
Sentence embeddings have enabled us to compare semantics of sentences numerically, which are now essential for tasks such as semantic textual similarity, semantic search and sentence clustering. Unlike keyword based search, which retrieves lexically similar contexts but not necessarily what you are looking for, semantic search retrieves only semantically relevant sentences to your query. For example, with a query “Thousands demanding climate change action”, we can retrieve a sentence “Copenhagen: protests against global warming” with semantic search, but not with keyword search.In particular, a rapid development of transformer based multilingual sentence embedding models over the past year now enables us to handle semantics of sentences across multiple languages with just one model. This can be done without needing to translate sentences, which risks distorting the original meaning with bad translation and is computationally expensive.So how well can these models identify semantic similarities of sentences, regardless of languages, i.e., being language agnostic? How well can they retrieve the most relevant document to a query, from a pool of multiple different languages? Some models were trained with cross-lingual translation pairs and are only intended to be used for translation. Thus little study has been done on investigating cross-lingual semantic textual similarity on semantically similar cross-lingual sentence pairs (instead of translation pairs, which are supposed to be semantically same).Primer ingests vast amounts of documents daily, and it is important that our systems can retrieve semantically similar documents accurately across multiple languages on news, social media, or companies’ internal documents.Here, we conducted a detailed evaluation of publicly available multilingual sentence embedding models by measuring semantic similarity of news titles in 33 languages, and by visualizing the embeddings spaces.
Getting similar news from a pool of news contents in 30+ languages
A truly language-agnostic multilingual language model is one where all semantically similar sentences are closer than all dissimilar sentences, regardless of their language.Examples of known multilingual sentence embedding models which were trained on a large number of languages are, LaBSE(109 languages) [1], multilingual SBERT(50+ languages)[2,3], and LASER3 (200 languages)[4]. Do these models perform well on retrieving semantically similar sentences from a pool of documents with 10s of different languages?Here we investigate the multilingual sentence embedding models on their ability to identify semantically similar (but not exactly same) sentences by taking a look at news titles in 33 languages. 15,210 multilingual news titles were scraped from all news articles that have links to English WikiNews in non-English languages. A list of languages in the dataset is, English, French, German, Portuguese, Polish, Italian, Chinese, Russian, Japanese, Dutch, Swedish, Tamil, Serbian, Czech, Catalan, Hebrew, Turkish, Finish, Esperanto, Greek, Hungarian, Ukrainian, Norwegian, Arabic, Persian, Korean, Romanian, Bulgarian, Bosnian, Limburgish, Albanian and Thai. Then, sentence similarity of the English news title and the foreign news title of the same news (positive pairs), as well as of the news which has no common categories (negative pairs) were calculated. For example, a WikiNews article titled “United Kingdom buries Queen Elizabeth II after state funeral” has linked articles in 11 other languages. Their titles are shown below.

On the other hand, a WikiNews article titled “Very serious': Chinese government releases corruption report”, which has no overlapping topics with the news above, has linked non-English news articles with following titles.

Since there are no common topics between these two news events, their titles should be dissimilar to each other regardless of the languages. For example, the following can be regarded as positive and negative sentence pairs for English - French news title pairs.

Positive English - target language sentence pairs were created from all English WikiNews pages that have international news pages linked to them, and negative English - target language sentence pairs were created from all possible sets of news articles that have no overlapping topics. The following shows the distribution of cosine similarity scores of positive and negative title pairs, grouped by languages. A box indicates the interquartile range of the distributions. Similarities were calculated using one of the three multilingual sentence embeddings SBERT(distiluse-base-multilingual-cased-v1), SBERT(paraphrase-multilingual-mpnet-base-v2), and LASER3.
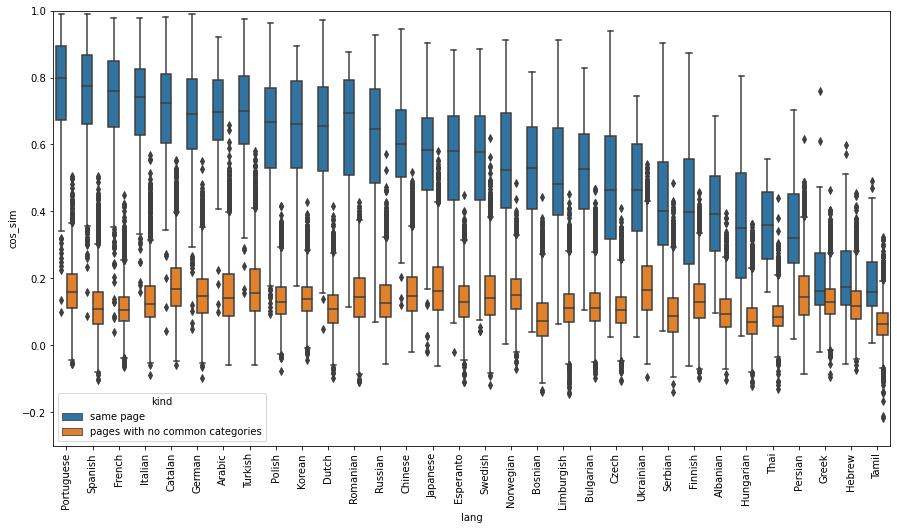
(a) SBERT distiluse-base-multilingual-cased-v1
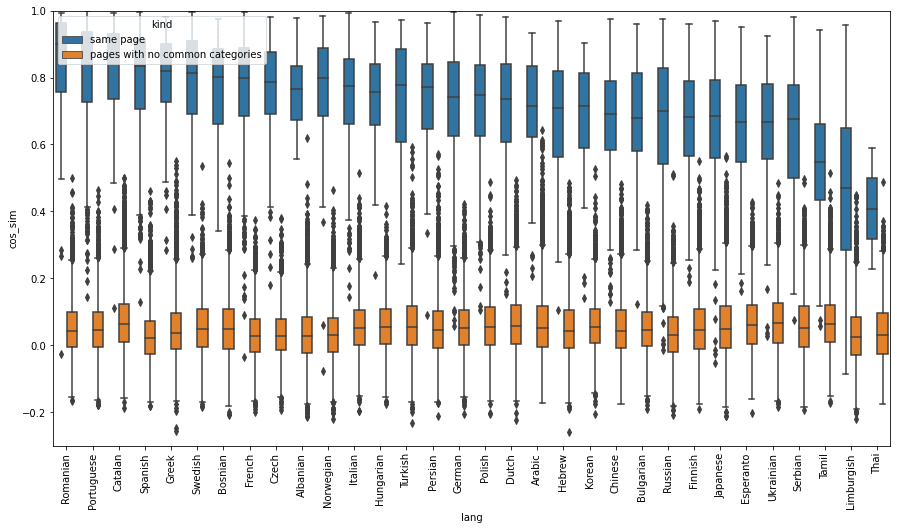
(b) SBERT paraphrase-multilingual-mpnet-base-v2
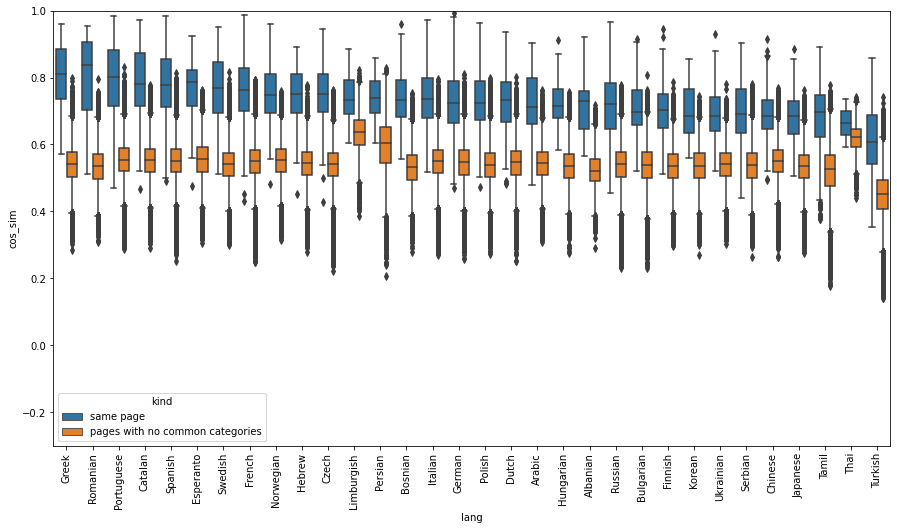
(c) LASER3Fig. Distribution of cosine similarity scores of positive ( cross-lingual pairs of same news) and negative (cross-lingual pairs of unrelated news) title pairs, grouped by languagesSBERT paraphrase-multilingual-mpnet-base-v2 model and LASER3 model have similar cosine similarity scores across all languages, except Tamil, Limburgish, and Thai in SBERT paraphrase-multilingual-mpnet-base-v2 model. On the other hand, on SBERT distiluse-base-multilingual-cased-v, average cosine similarity of positive sentence pairs varies widely depending on languages, from ~0.8 in Portuguese to ~0.2 in Tamil. Due to the language bias, a sentence retrieval model built with this embedding model could rank Portuguese sentences that are not that similar to an English query much higher than a Hebrew sentence which has the exact same meaning as the query.LASER3 gives higher cosine similarity scores for positive pairs (average 0.7~0.8), but also for negative pairs (average ~0.55, in contrast to average 0.05 for SBERT). Even though LASER3 was trained on 200 languages including all 32 foreign languages that are on our evaluation datasets, they struggle to distinguish between similar news titles and dissimilar news titles on some English-foreign language (e.g., Thai) title pairs. We can conclude that SBERT(paraphrase-multilingual-mpnet-base-v2) is the best of the three models discussed here for the multilingual sentence similarity search task, since the differences between the cosine similarities of positive sentence pairs and the negative sentence pairs are the largest on average. This result shows that it is important to know if your model has a language bias in languages of your interest.Note here that positive sentence pairs used here are not exactly semantically same, as you see in the example positive pairs shown above (e.g.., a positive pair “United Kingdom buries Queen Elizabeth II after state funeral” and ”大不列顛及北愛爾蘭聯合王國女王伊麗莎白二世陛下逝世,享耆壽96歲 (translated: Her Majesty Queen Elizabeth II of the United Kingdom of Great Britain and Northern Ireland dies at 96)”). Thus, we don't expect cosine similarities of the positive pairs to have the value exactly, or very close to 1.
Visualization of the Distribution of Sentence Embeddings By News Topics
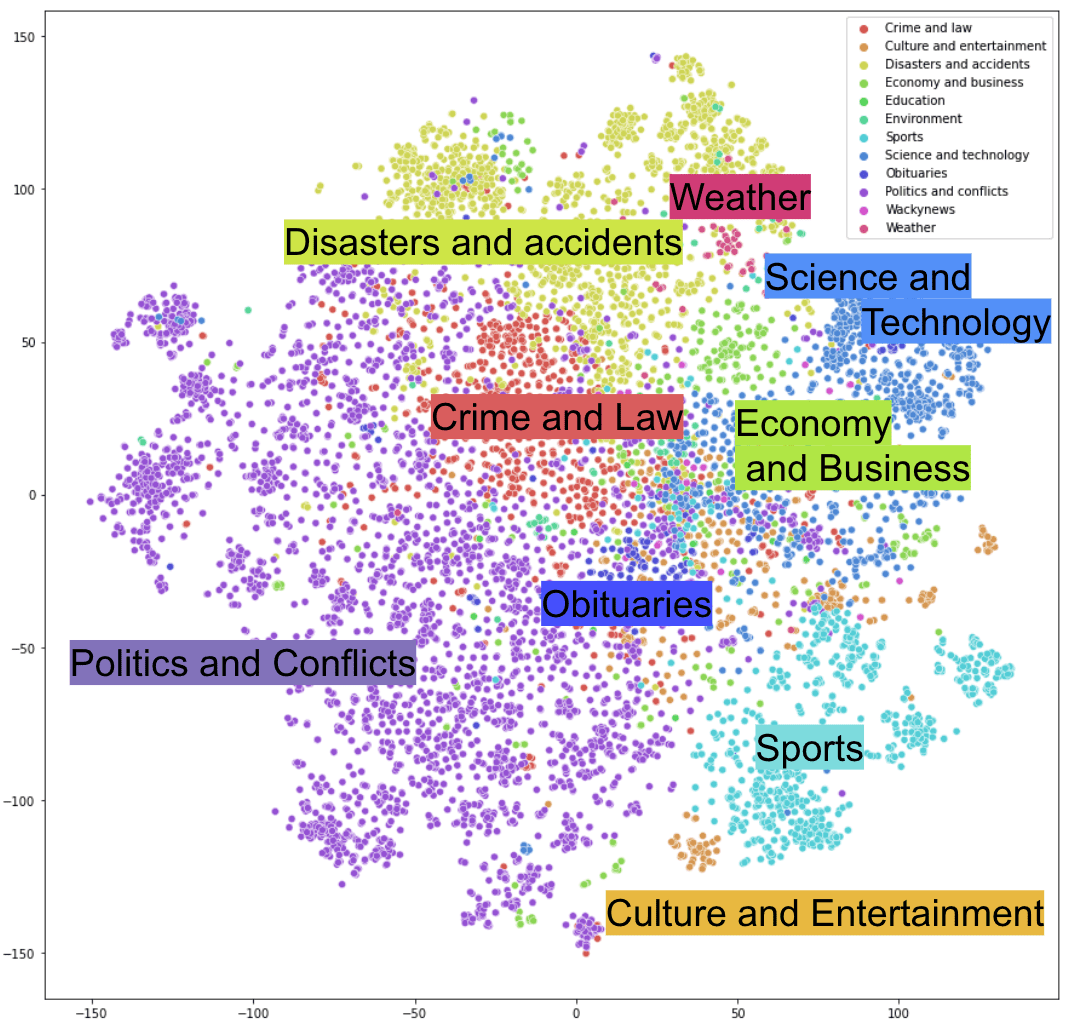
To further understand how embeddings of news titles are distributed in the multilingual semantic embedding spaces, we visualized them in 2 dimensions. A figure below shows the distributions of news titles embedded with the SBERT(paraphrase-multilingual-mpnet-base-v2) model. The dimension of the embedding space was reduced to 2D using a dimensionality reduction technique called t-SNE, which preserves local structure of the clustering.Sentence embeddings are colored 13 news topics defined by the WikiNews: Crime and law, Culture and entertainment, Disasters and accidents, Economy and business, Education, Environment, Heath, Obituaries, Politics and conflicts, Science and technology, Sports, Wackynews, Weather. Here, I excluded news titles which have more than one of the 13 topics.
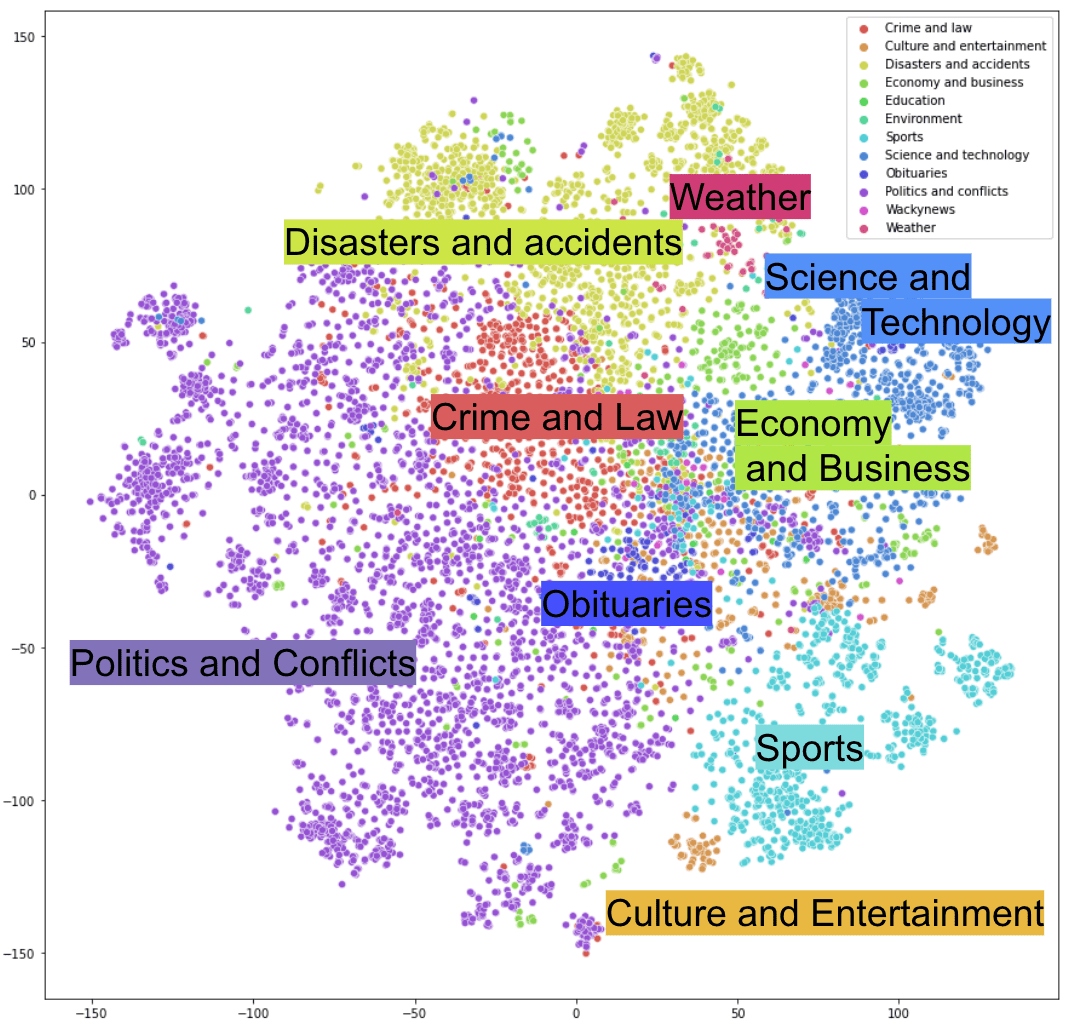
Fig. SBERT (paraphrase-multilingual-mpnet-base-v2) embeddings of WikiNews titles (34 languages) with its dimension reduced to 2D with t-SNE methodWe can see the embeddings of multilingual news titles clustered together by news topics, indicating that our embedding space contains meaningful information about the topics seen in the news.
Fast Search on Multilingual Corpora
Here we showed that multilingual sentence embedding models are potentially powerful tools, and it is important to understand the language bias when using them for multilingual semantic search tasks.Semantic search using a multilingual embedding model gives us great advantage in many ways. Compared against first translating documents and then using the Okapi BM25 algorithm, which is a well known bag-of-words retrieval function, semantic search using multilingual dense embedding models enabled us to retrieve news articles of the same events with higher precision and recall, and more relevant news, without ever worrying about the language of the text. Furthermore, computing dense embeddings is much faster than translating sentences in general, and we find that pre-computing time for this semantic search using SBERT (paraphrase-multilingual-mpnet-base-v2) model was more than 100 times faster than the keyword based model using the light translation model nllb-200-distilled-600M. These trends apply to a wide range of document types beyond news, from short social media posts, to companies’ internal documents with varying text lengths and domains. At Primer, we constantly seek the best solution to retrieve, cluster and understand documents efficiently and accurately, and those documents are not limited to English, but any texts that exist in the world.—
Reference
[1] Language-agnostic BERT Sentence Embedding (Feng et al., ACL 2022)[2] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (Reimers & Gurevych, EMNLP-IJCNLP 2019)[3] Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation (Reimers & Gurevych, EMNLP 2020)[4] No Language Left Behind: Scaling Human-Centered Machine Translation (NLLB Team, arXiv:2207.04672, 2022)Explore more developer related content here.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



