Maverick, Goose begin romantic relationship
Welcome to the age of machine-generated headlines
- How to write news headlines
- Can we write document summaries?
- The simplest summarization model
That is a machine-generated summary of this article. I fed the text through a deep learning model that we’re training here at Primer where we’re building machines that read and write. The three-bullet point summary above took less than a second running on a single 2080Ti GPU.
Now you don’t have to read it. You’re welcome! (To understand the machine-generated title, you’ll have to read to the end.)
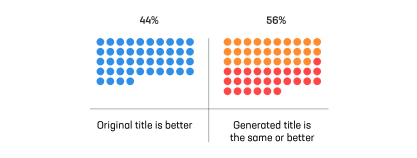
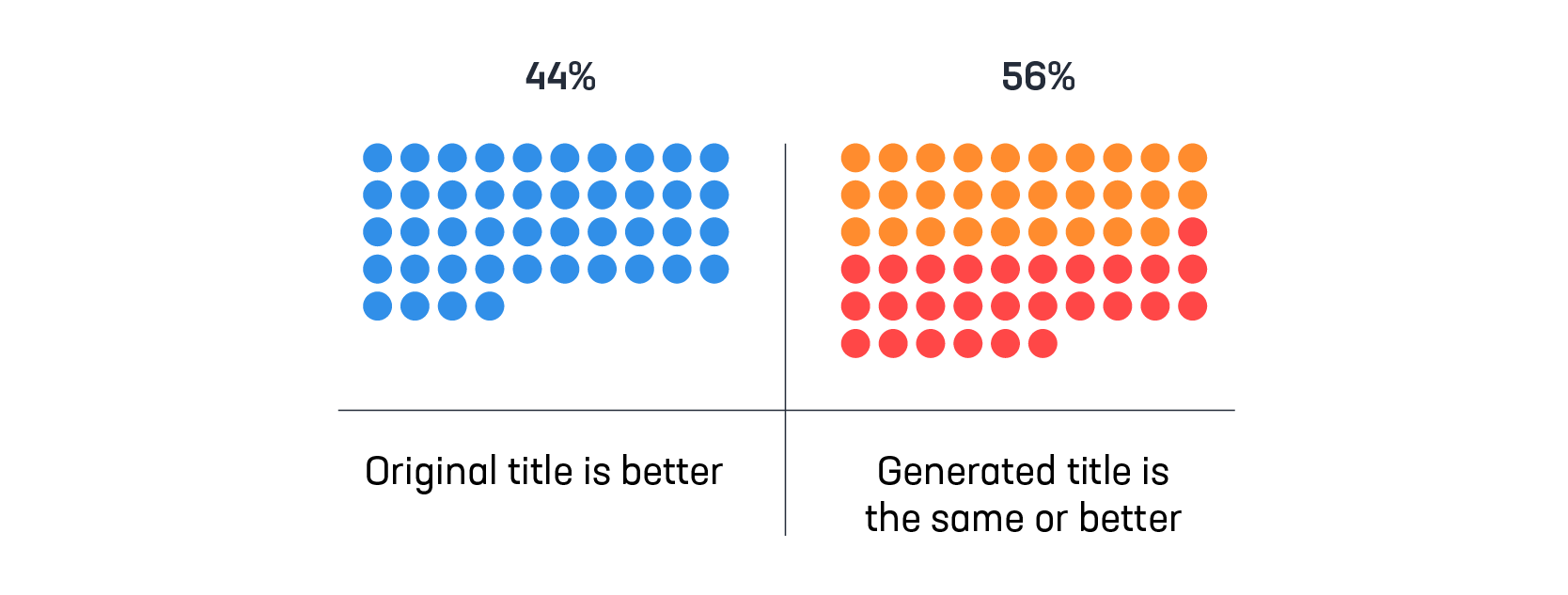
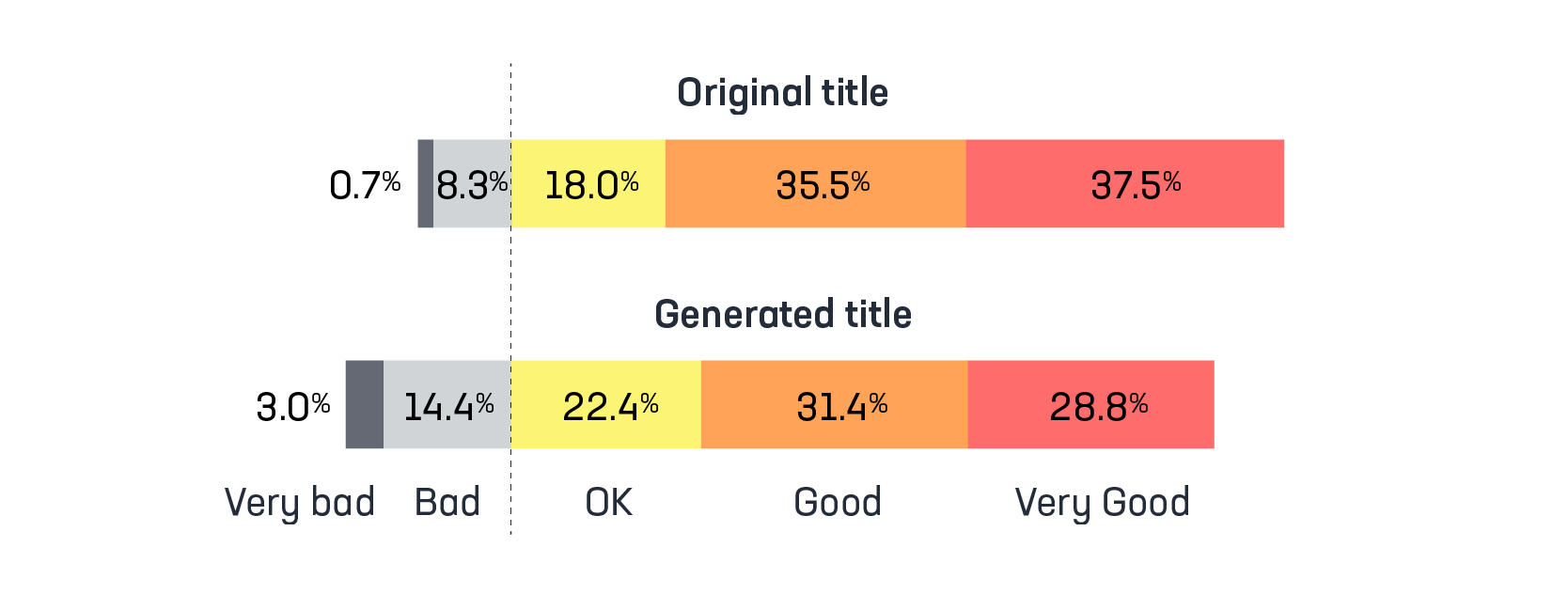
The base model that makes this possible is laid out in our recently published paper. We fine-tuned the BERT universal language model on millions of news headlines. The model learned to generate titles for documents as an iterative question-answer task. It takes about 1.5 million news articles for the model to learn how to generate headlines as good or better than the originals in the majority of cases.
Question: Can a neural network write headlines as good as those written by humans?
Answer: Yes, especially when the headlines are clickbait.
Journalists have conflicting motivations when writing headlines. The main task is to inform the reader, giving her a short and meaningful description of what the document contains. But much of the success of online news relies on clicks. Headlines must entice people to read stories that display the ads that pay the bills. Luckily, clickbait headlines are a very small portion of Primer’s news corpus—far less than 1% of our hundreds of millions of English-language news articles. The model learned its writing style from good journalism.
This is what it looks like when a machine re-writes clickbait headlines:
humanThe Obamas Are Getting a Netflix Show, & You Won’t Believe Who It’s FormachineThe Obamas are getting a show for kidshumanYou’ll never guess which U.S. counties grew the fastestmachineMcKenzie County in North Dakota had highest population growth in entire UShumanThe Title Of This Court Filing Will Amaze You!machineBuzzFeed sued for defamation of Russian hacking defendants
Here is a more representative sample of news articles. In the majority of cases, the machine-generated headlines are as good or better than the originals, as scored by humans in double-blind trials:
humanBad Movie Diaries: A Christmas Prince: The Royal Wedding (2018)machineJim Vorel and Kenneth Lowe discuss A Christmas Prince and its sequel, The Royal WeddinghumanABC chairman job: Academic, legal and media executives make the shortlistmachineFormer Allens partner Michael Rose among candidates for ABC chairmanhuman‘It’s been a long 2 years’ for Kelly, Kudlow saysmachineJohn Kelly replacement to be announced in next few dayshumanDecision in March on 48-team 2022 World Cup, says InfantinomachineFIFA to decide on 2022 World Cup in MarchhumanKhal Drogo Is Alive—Sort of—on This Week’s ‘Saturday Night Live’machineKhal Drogo is back on SNL
Ideally, a document’s title should serve as an extremely short but informative summary of its content. Our title generation model is lazy, reading the text of a document only until it finds what seems to be sufficient information to generate that one-line summary.
When the model falls short, it is often because it is confused by longform journalism which is rare in its training data. It focuses on information near the top of the story, simply because that is where most news articles get to the point. Longform journalism has a different structure:
humanI Fooled Millions Into Thinking Chocolate Helps Weight Loss. Here’s How.machinePeople lost weight faster if they ate a chocolate bar every dayhumanWho’s downloading pirated papers? EveryonemachineHow to read the scientific papershumanGamers unravel the secret life of proteinmachineProtein chemistry: David Baker
We could improve our generated titles with rules. But the best way forward is to build a better model by training it on more abundant, higher-quality data. Luckily we have several orders of magnitude more news articles on tap.
Question: Can a title-generating neural network be repurposed to write full document summaries?
Answer: Surprisingly, yes.
For the past few weeks we have been playing with a simplified model. We feed a document into the title generation model and track how deeply it reaches into the text to write a title. Then we feed in the text below that point and generate another. Each “title” becomes the next line in a bullet-point summary. When it reaches the end of the text, the summary is done.
In spite of being completely unsupervised and requiring no additional training, this naive summarization algorithm performs reasonably well right out of the gate.
Here are some human vs. machine-generated summaries, drawing from the CNN/Daily Mail data set:
Police: Teen wanted for killing at Seattle bar hosting Seahawks, fans
human
- Suspect is 19, police say
- CNN affiliate KING reports that several NFL players were in the bar at the time
- Reality star tweets that she saw body on the floor and a lot of blood
machine
- Teen shot, killed in Seattle-area bar where Seahawks players and other celebrities were partying
- Bellevue Police still searching for suspect in murder of ‘Tuba Man’
- Seahawks ‘ Greg Scruggs tweets The death of the popular musician who played his tuba
- I saw the guy laying on the floor and blood everywhere
Man, 37, arrested in probe of ricin-laced letters found in Washington state
human
- NEW: Matthew Buquet will stay in custody until at least next Tuesday, FBI says
- The 37-year-old threatened to “injure and kill” a federal judge, an indictment alleges
- Tests showed ricin was found with the threatening letter, the FBI says
- He was arrested Wednesday afternoon in Washington state
machine
- Man arrested in ricin (CNN) threat investigation
- Matthew Ryan Buquet arrested by FBI
- Ricin suspected in letters sent to Spokane Post Office
- Ricin is no known antidote
Deep-voiced bosses bring in the big bucks, says study
human
- A new study shows that the lower a CEO’s voice, the larger his company and paychecks tend to be
- It is still unclear why lower-voiced CEOs are more successful
- Image consultants say executives can learn to alter voice pitch
- Leaders can also convey power by how they dress
machine
- Study shows that CEOs tend to be taller
- Why labor market is matching real CEOs
- Voice pitch could also be related to other physical characteristics that suggest dominance
- Mayew: ‘ There are certain bounds that we’re just born with ‘
- The power of words
- How to dress in the workplace, executives should dress in one color, which adds height, and wear plain fabric rather than patterned styles
Remarkably, the model can summarize non-news documents, even though it’s never seen examples. We need this capability at Primer because our customers have their own documents they need to rapidly skim—financial analyst reports, scientific papers, intelligence briefings—before choosing the ones to fully read.
Wikipedia movie plot overviews are a good open-source proxy. This is how our prototype model performs:
machine
- Joker and Harvey Dent form alliance for Gotham organized crime
- The Joker offers to kill Dent for half of their money
- Joker kills Gambol and taking over his gang
- Batman brings the Joker back to Gotham
- The Joker threatens to keep killing people unless Batman reveals identity
- Dent kidnaps Joker
- Joker attacks convoy
- Batman apprehends Joker who killed Rachel and Dent
machine
- Maverick and Cougar fly F-14A Tomcat on USS Enterprise
- Maverick shepherds Cougar back to the carrier
- Maverick and Topgun
- Maverick defeats Topgun instructor During first training sortie
- Maverick becomes rival to Iceman
- Maverick, Goose begin romantic relationship
- Maverick considers retiring
- Iceman seeks advice from Viper, who reveals that he served with Maverick’s father Duke Mitchell on the USS Oriskany
The errors that the model makes involve entities. It correctly identifies key events that should be included in the summary, but it incorrectly guesses who is involved. What’s needed is a fact-aware text generation system: a knowledge base that can read and write. By pre-annotating the input text with entity embeddings from Quicksilver, our self-updating knowledge base, our model can learn to keep better track of who’s who.
In Top Gun, Maverick begins a romantic relationship with his flight instructor Charlie, not Goose his copilot. But perhaps we should treat this as a deeper truth and a glimpse at the future. As machine understanding becomes ever more sophisticated, we humans will come to rely on machines that reveal truths deeper than we can see.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



