Machine-Generated Knowledge Bases
Human-generated knowledge bases like Wikipedia have a recall problem. First, there are the articles that should be there but are entirely missing. The unknown unknowns.
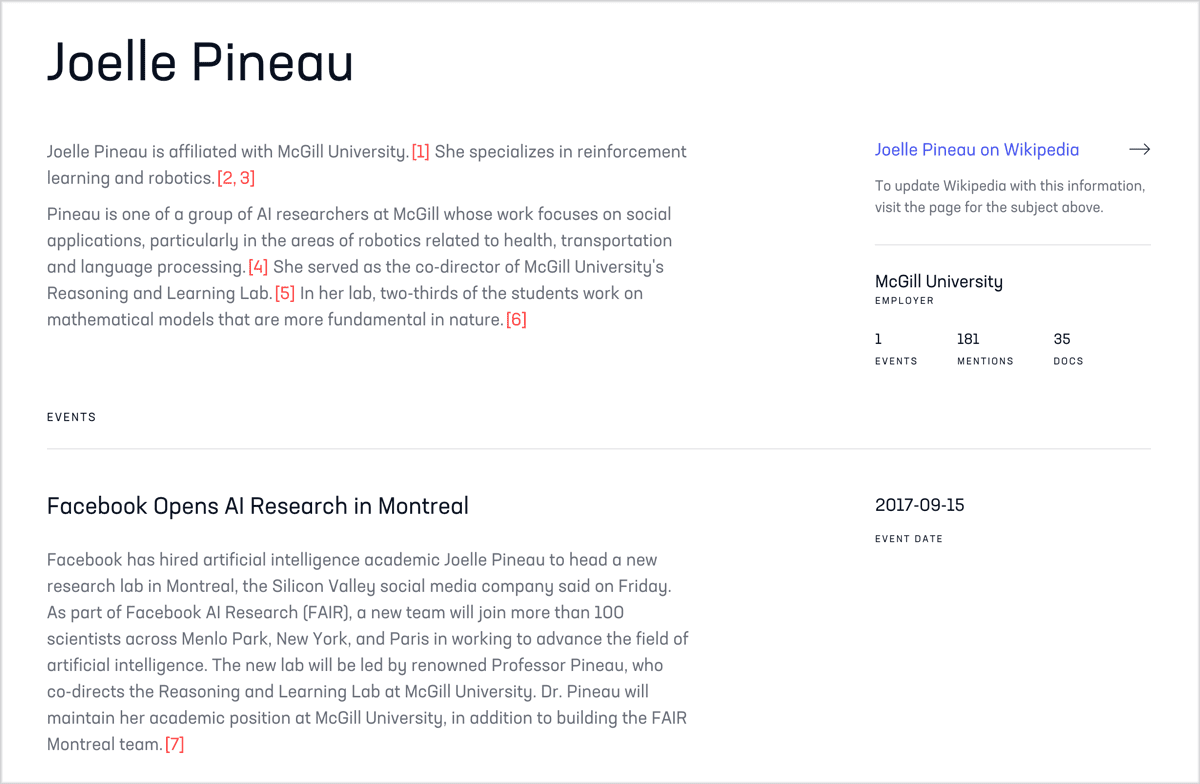
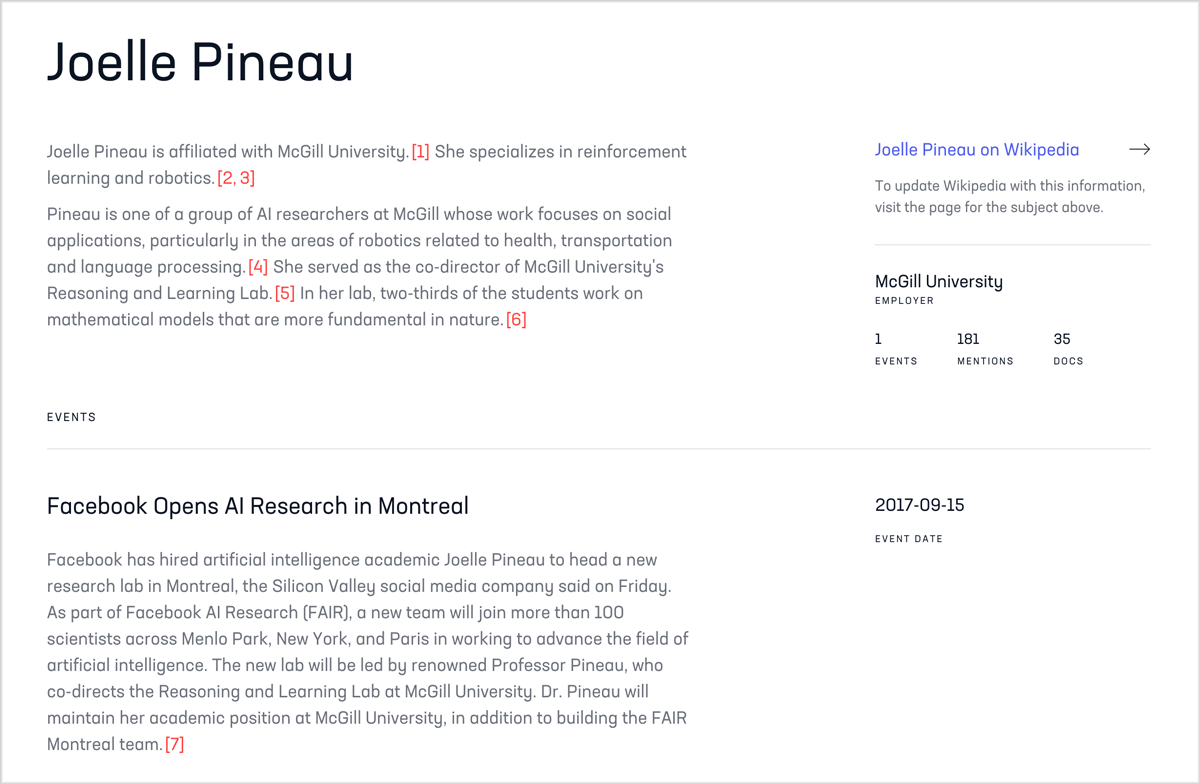
Consider Joelle Pineau, the Canadian roboticist bringing scientific rigor to artificial intelligence and who directs Facebook’s new AI Research lab in Montreal. Or Miriam Adelson, an actively publishing addiction treatment researcher who happens to be a billionaire by marriage and a major funder of her own field. Or Evelyn Wang, the new head of MIT’s revered MechE department whose accomplishments include a device that generates drinkable water from sunlight and desert air. When I wrote this a few days ago, none of them had articles on English Wikipedia, though they should by any measure of notability.
(Pineau is up now thanks to my friend and fellow science crusader Jess Wade who created an article just hours after I told her about Pineau’s absence. And if the internet is in a good mood, someone will create articles for the other two soon after this post goes live.)
But I didn’t discover those people on my own. I used a machine learning system we’re building at Primer. It discovered and described them for me. It does this much as a human would, if a human could read 500 million news articles, 39 million scientific papers, all of Wikipedia, and then write 70,000 biographical summaries of scientists.
We call it Quicksilver. It’s a nod to Neal Stephenson’s Baroque Cycle, wherein a technology is imagined that captures all human knowledge “in a vast Encyclopedia that will be a sort of machine, not only for finding old knowledge but for making new.” Because we’re nerds.

We are publicly releasing free-licensed data about scientists that we’ve been generating along the way, starting with 30,000 computer scientists. Only 15% of them are known to Wikipedia. The data set includes 1 million news sentences that quote or describe the scientists, metadata for the source articles, a mapping to their published work in the Semantic Scholar Open Research Corpus, and mappings to their Wikipedia and Wikidata entries. We will revise and add to that data as we go. (Many thanks to Oren Etzioni and AI2 for data and feedback.) Our aim is to help the open data research community build better tools for maintaining Wikipedia and Wikidata, starting with scientific content.
Fluid Knowledge
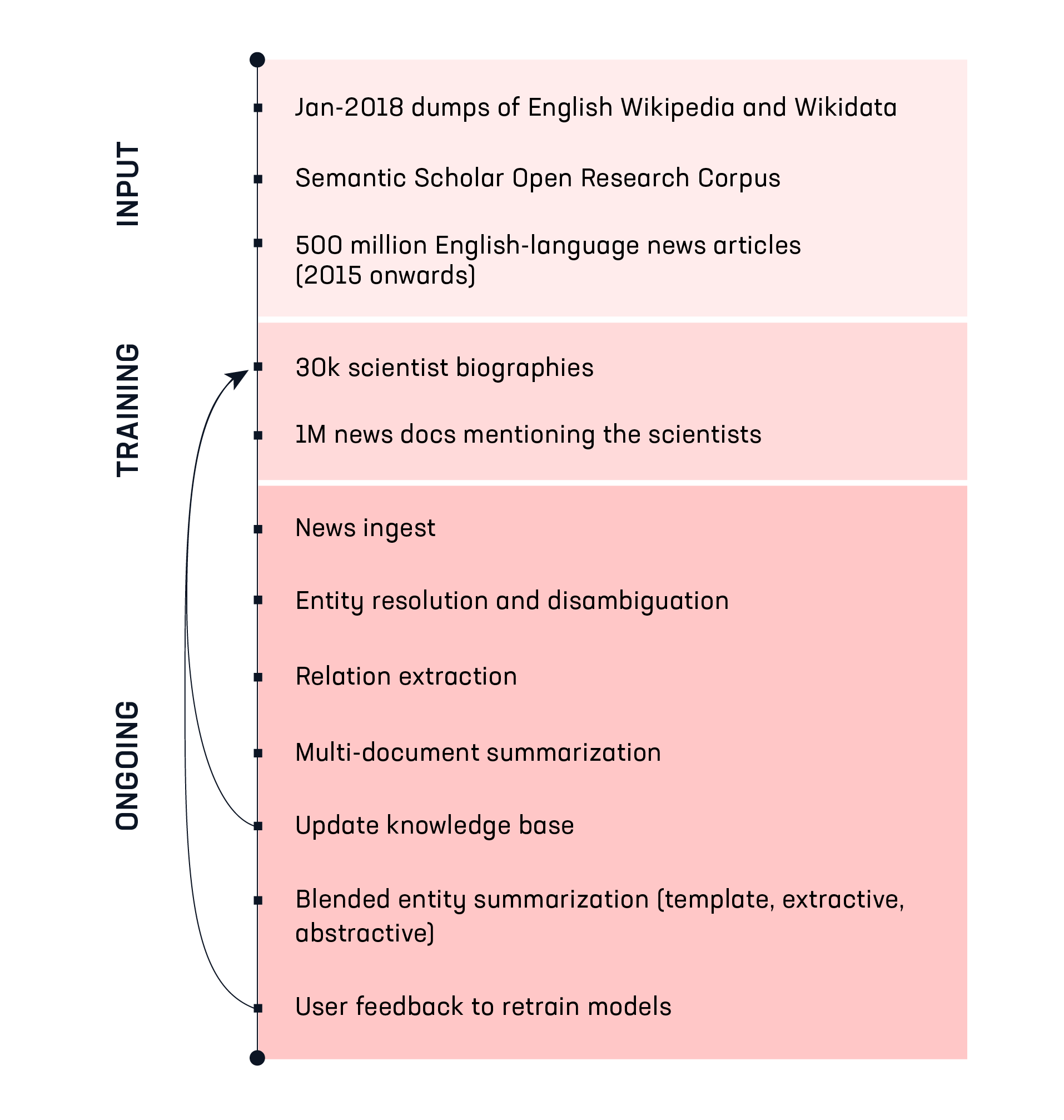
We trained Quicksilver’s models on 30,000 English Wikipedia articles about scientists, their Wikidata entries, and over 3 million sentences from news documents describing them and their work. Then we fed in the names and affiliations of 200,000 authors of scientific papers.
In the morning we found 40,000 people missing from Wikipedia who have a similar distribution of news coverage as those who do have articles. Quicksilver doubled the number of scientists potentially eligible for a Wikipedia article overnight.
It also revealed the second flavor of the recall problem that plagues human-generated knowledge bases: information decay. For most of those 30,000 scientists who are on English Wikipedia, Quicksilver identified relevant information that was missing from their articles.
Creating an article for a person is only the start. It must be maintained forever, updated as the world changes. The vast majority of information on Wikipedia is known to be correct and well cited, even after more than a decade of stunts and studies to prove otherwise. But as Fetahu et al. showed last year, Wikipedia lags significantly behind news about people and events.
Take for example Ana Mari Cauce, the president of the University of Washington. Her Wikipedia article went stale last year. Quicksilver discovers more recent information about Cauce’s defense of DACA students and her ongoing role in the free speech vs. hate speech battles on US campuses.
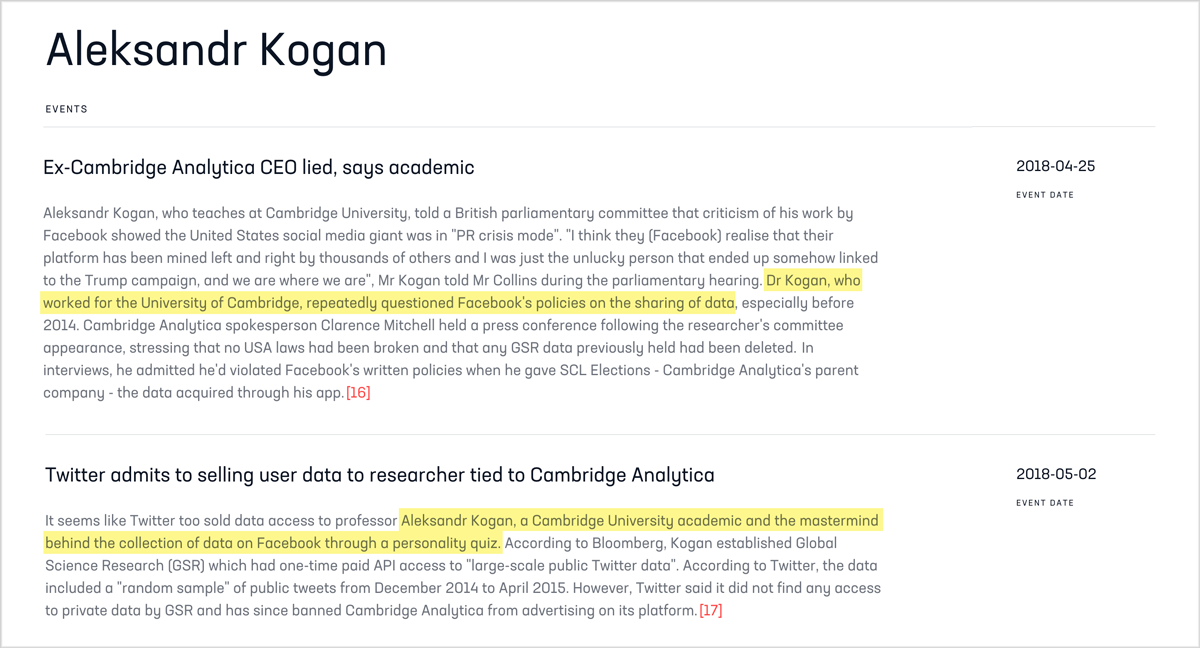
The Quicksilver output for Aleksandr Kogan is also enlightening. The psychologist’s English Wikipedia article was created in March 2018 when the Cambridge Analytica scandal blew up around him. But the trail goes cold on 26 April, the date of his article’s most recent reference. Quicksilver identifies an event for Kogan just four days later, the revelation that he had his hands on Twitter data as well. Twitter is now cracking down on data access.
Summarizing a person
Automatically generating Wikipedia-style articles is right at the edge of what is currently possible in natural language processing. It is usually framed as a multi-document summarization task: Given a set of reference documents that contain information about an entity, generate a summary of the entity.
One of the earliest attempts to generate Wikipedia-style biographies—a decade ago by Biadsy et al. at Columbia—used extractive summarization. The algorithm ranks and snips relevant sentences from the source text and sews them together into a final Frankentext. The advantage is that the sentences are all coherent because they were written by humans. But it comes with a tradeoff in expressivity. The machine can only write what has been written already by humans.
More recently, researchers are turning to abstractive summarization. This technique uses a neural language model to generate text on the fly. It has a tradeoff in coherence, with outputs often veering into the nonsensical. A clever compromise by See et al. at Stanford gives abstractive models an extractive fallback option through a pointer-generator network. (See our blog posts on some of the promises and challenges of this technique.)
A team led by one of the co-authors of the pointer-generator paper, Peter Liu at Google AI, took a crack at automatic Wikipedia article generation recently. They used extractive summarization as a first step to constrain the input text, and then abstractive for the final output step. When it works—they include impressive sample outputs in their appendix—the technique is quite expressive, capable of producing multiple coherent paragraphs that never existed.

For Quicksilver’s architecture we started on the trail blazed by the Google AI team, but our goal is more practical. Rather than using Wikipedia as an academic testbed for summarization algorithms, we’re building a system that can be used for building and maintaining knowledge bases such as Wikipedia. We need to track data provenance so that any statement in the final text output can be referenced to its source. We also need structural data about entities and their relations so that we track changes of fact, not just text. And to achieve high precision, there just aren’t enough biographies with enough clean source document mappings to train today’s seq2seq models. They can’t learn the tacit knowledge required. What’s needed is a knowledge base coupled with a seq2seq model.
Lucky for us, the world’s most comprehensive public encyclopedia is tightly coupled with the world’s most comprehensive public knowledge base: Wikidata. The crucial breakthrough for us was using structural data from Wikidata about our seed population of scientists to map them to their mentions in news documents. Distant supervision then allowed us to bootstrap models for relation extraction and build a self-updating knowledge base. By adding an RNN trained on Wikipedia articles, it becomes a knowledge base that can describe itself in natural language.
We’ve been quietly testing and improving Quicksilver for months. Even before we finished the text generation component, Quicksilver was used in three English Wikipedia editathons for improving coverage of women of science. (Thank you to 500 Women Scientists for collaborating and inspiring us!)
We will describe our architecture in detail in future posts but here is a compressed summary of how Quicksilver works:
As an experiment, we are publishing a sample of 100 short Quicksilver-generated summaries of scientists missing from Wikipedia. We’re curious how long it will take before someone creates their articles.
The future of knowledge
It’s hard to grasp just how important Wikipedia has become for the world, and how vulnerable. It is the fifth most visited website, serving more than 15 billion pageviews per month. It includes nearly 50 million articles, written in almost 300 languages—only 13% in English. It boggles the mind that all of this is created by human volunteers.
The human authorship of Wikipedia is its strength. The deliberative process of the editors ensures that Wikipedia remains robust and tends toward consensus. Just visit Twitter to see what a non-deliberative information platform looks like where bots roam free.
But with human hands come human limitations. As it becomes more and more essential to the world, biased and missing information on Wikipedia will have serious impacts. The human editors of the most important source of public information can be supported by machine learning. Algorithms are already used to detect vandalism and identify underpopulated articles. But the machines can do much more. They can track and summarize information missing from Wikipedia articles. They can even identify articles that are missing altogether, and generate the first draft.
To solve the recall problem of human-generated knowledge bases, we need to superpower the humans.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



