Chinese Word Vectors

皇帝 + 女人 – 男人 → 武则天
Emperor (or king) + Woman – Man → Zetian Wu
In natural language processing, words can be thought of as vectors in a low-dimensional space. This allows you to manipulate language to discover relations that are otherwise difficult to discover. A famous example is to add the vector for ‘woman’ to the vector for ‘king’ and then subtract ‘man’, yielding the vector for ‘queen’. Although they have different vocabularies and grammar rules, all human languages are fundamentally similar. So it should be possible to use this vector-based strategy in any of them. In this blog, you will see how to get the Chinese version of king + woman – man → queen.
In the next section, we give an overview of word vectors. Feel free to skip it if you are familiar with the concept. Next, we show how to train Chinese word vectors using Gensim. We then show examples of Chinese word vectors including the Chinese version of king + woman – man → queen. We end with a brief discussion of how to choose Chinese word vectors.
Word Vectors
An easy way to represent words in vectors is to use one-hot encoding. This method uses a one-to-one mapping from each word in the vocabulary to an entry in a sparse vector matrix. A word is represented as all 0s with a 1 at the corresponding location. For example, let’s say you have a corpus with only six words: king, queen, man, woman, smart and intelligent. (Example borrowed from blog The amazing power of word vectors with slight modification.) The one-hot representations are:
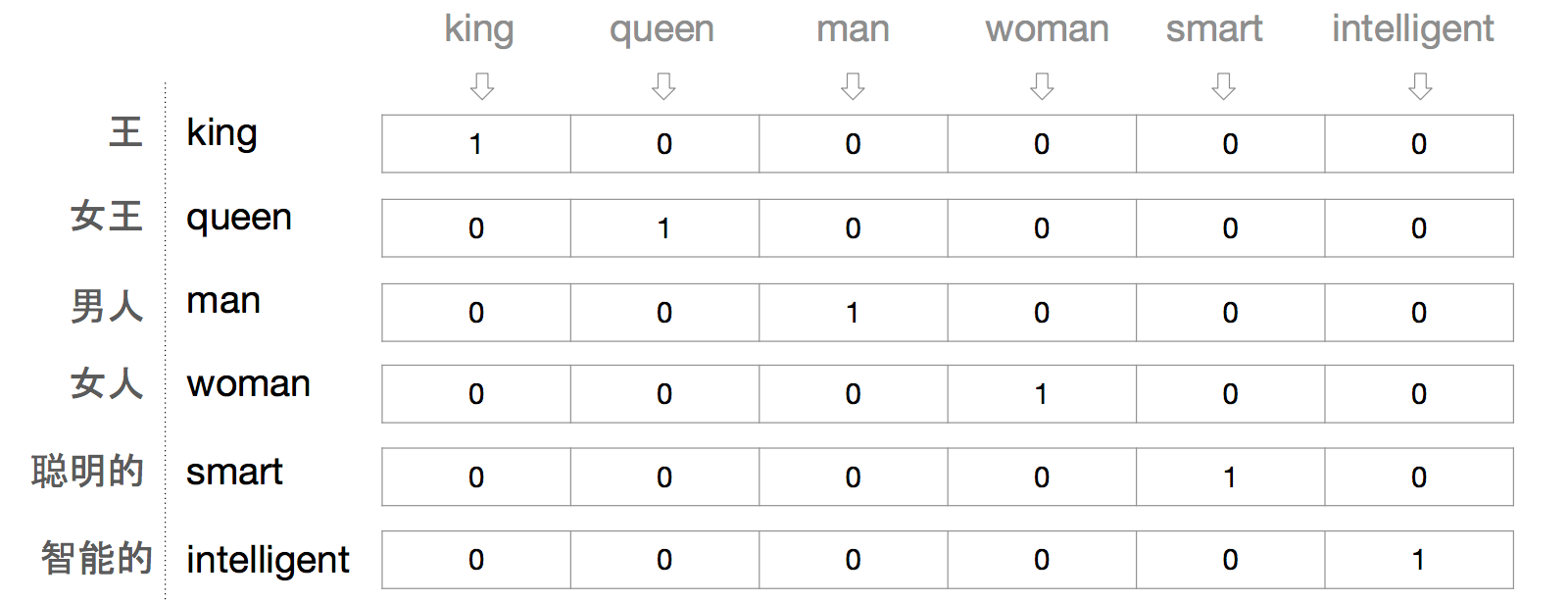
Due to its simplicity, one-hot word representation has been widely adopted in natural language processing (NLP). The main drawback is that it doesn’t take into account any semantic relations between words. For example, you couldn’t tell if ‘smart’ is similar to ‘intelligent’, or how ‘king’ and ‘queen’ might be related.
To solve the problem, word embedding (or distributed word representation) encodes the semantic meaning of a word as a low-dimensional vector. Intuitively, each entry in the vector contributes to a certain aspect of the word’s definition. For example, you could represent “king, queen, woman, man, smart, and intelligent” with a 3-dimensional vector:

(Note: the numbers are chosen for illustration purpose only)
By comparing the vectors (i.e., using cosine similarity), you can determine that ‘smart’ is very similar to ‘intelligent’. You can also determine a relationship between ‘king’ and ‘queen’ :
king+woman−man
= [0.9,−0.9,0.5]+[0.1,0.9,0.5]−[0.1,−0.9,0.5]
= [0.9,0.9,0.5]
= queen
By capturing these semantic relationships, word embeddings are highly useful for NLP applications such as translation systems, text generation, and semantic analysis [1].
Word Vector Training Tools
Word vectors sound amazing, but how do you create them? They must be trained with a large-scale text corpus. There are two popular training algorithms: Google’s word2vec [1] and Stanford’s GloVe [2]. Both are unsupervised learning methods that capture words’ semantic properties by considering their co-occurrence with other words. You can download pre-trained English word vectors from the algorithms’ websites: word2vec or GloVe. For other languages, Facebook [5] published word vectors for 294 languages (including Chinese and Russian), trained on Wikipedia.
Although pre-trained word vectors are available, sometimes you may want to train your own. For example, you may have a text corpus in a different language, or you may want to perform some special pre-processing on a corpus in advance.
So, let’s look at some code for word vector training. You can use a free Python library Gensim to train, save and load word vectors. Let’s try Google’s word2vec as the training algorithm.
from gensim.models import Word2Vec
# Train your model! Set the word vector dimensionality as 300 (size)
# and ignore the words that appear less than 5 times (min_count).
model = Word2Vec(sentences, size=300, min_count=5)
# Enable saving and loading of your trained model.
model.save('wv')
model = Word2Vec.load('wv')
(See Gensim’s API and this blog for available parameters)
In the above code, the input is a sequence of sentences. Every sentence is represented as a list of words. You can pre-process the sentences any way you want. For example, given a corpus: “A queen is a woman. A king is a man.”, you might get :
sentences = [['a', 'queen', 'is', 'a', 'woman', '.'],
['a', 'king', 'is', 'a', 'man', '.']]
If you choose to remove stopwords and punctuations, then you get:
sentences = [['queen', 'woman'], ['king', 'man']]
Chinese Word Vectors
How do you train Chinese word vectors? Luckily, you can use the very same algorithm. The challenge lies in dividing a Chinese sentence into smaller, coherent units. A natural approach in English is to work at the level of individual words. How about in Chinese? To illustrate the problem, let’s take a look at a quote from Harry Potter and the Prisoner of Azkaban in Chinese:
Happiness can be found, even in the darkest of times, if one only remembers to turn on the light.
即使在最黑暗的日子,幸福也是有迹可循的,只要你记得为自己点亮一盏灯。
(sentence s1)
On the English side, you generate the word list simply by splitting the sentence on spaces. But in written Chinese, there are no spaces between words! Even stranger, and very unlike English letters, Chinese characters have their own meaning, which is crucial for encoding the meaning of the sentence.
Chinese Segmentation
To segment a Chinese sentence into even smaller meaningful units, you can split the text on characters, treating each one as an element in the vocabulary. For example, “即使在最黑暗的日子,” in sentence s1 can be divided into:

This method is straightforward to implement, but it has a fatal flaw. Chinese characters can take on completely different meanings in different contexts. For example, the character 子 in the word 儿子 means son, while 子 in the word 日子 is a noun suffix with no specific meaning. The character 点 in the word 点亮 means to turn on (the light). But 点 in 一点儿 means a little or a few. Therefore, many of the resulting word vectors would lose their meaning.
A far better strategy for Chinese segmentation is to do what Chinese speakers do: Break the sentence down into the words that have specific semantic meanings. For example, “即使在最黑暗的日子,” in the Harry Potter sentence s1
can be segmented as follows:

To segment Chinese text into meaningful words, you can use Jieba (结巴分词), an MIT-licensed, easy-to-use Python tool. To split the sentence, do this:
import jieba
sentence = u'即使在最黑暗的日子,幸福也是有迹可循的,只要你记得为自己点亮一盏灯。'
words = jieba.lcut(sentence)
Jieba makes use of a large Chinese word dictionary to segment Chinese text. It also uses HMM (Hidden Markov Model) and the Viterbi algorithm to capture new words. It gets 0.92 and 0.93 f-scores on datasets from Peking University and City University of Hong Kong, respectively. There are other methods for achieving even better performance. To learn more, check out more recent algorithms for Chinese segmentation [6,7].
Chinese Word Embeddings
With different segmentation methods, you get different inputs to the word2Vec algorithm. Consequently, you get different Chinese embeddings. Splitting Chinese text into a list of characters gets us to character embeddings, while semantic segmentation yields word embeddings.
With character embeddings, every Chinese character is encoded as a vector. So if a character has similar meanings in different words, this encoding makes sense. For example, the character 智(wisdom) has similar meanings in the words 智能 (intelligent), 智慧 (wisdom), and 智商 (intelligence quotient). But this is a dangerous assumption. As we discussed earlier, the character 点(point) takes on very different meanings in 点亮 (turn on/ignite) and 一点儿 (a little). Mixing multiple definitions in one vector will cause you pain.
Word embeddings solve this mixed-meaning problem by encoding every word to one vector — as compared to a character, a word usually doesn’t have multiple meanings. The downside of word embeddings is that it doesn’t make use of characters having the same meaning across words. So is it possible to take advantage of both facets of Chinese script?
It is. To capture characters that are part of many words, you can use char+position embedding — a compromise between word and character embeddings [3,4]. With char+position embeddings, every element in the vocabulary is a character with a position tag. The tag represents the character’s position in a word. For example, 点0 refers to 点 when it appears at the first position of words, whereas 点1 refers to 点 occurring at the second position of words. You can get character positions by word segmentation. “即使在最黑暗的日子,” in the sentence si then would be segmented as:
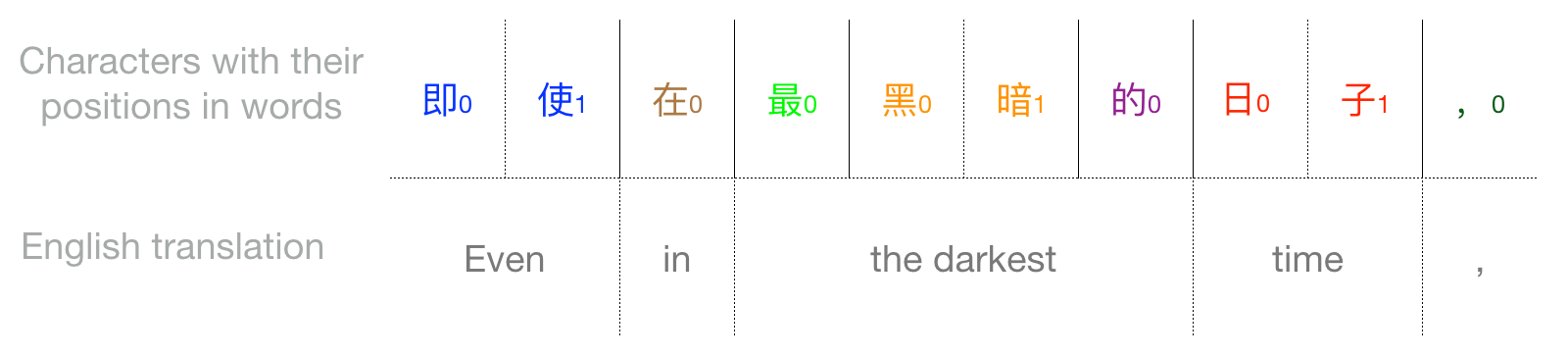
Char+position embedding assumes that a character has similar meanings when it appears at the same position in words. For example, 点 in both 点亮 and 点燃 means turn on/ignite. It’s not always true, but it helps reduce the word encoding to a much smaller set of character-position combinations.
Training
Recall that to train word vectors, you need sentences as input. Character, word, and char+position embeddings require different methods to generate sentences. Here is a code snippet to segment a sentence for the three embeddings:
import jieba
def get_chinese_characters(sentence):
"""Return list of Chinese characters in sentence. """
return list(sentence)
def get_chinese_words(sentence):
"""Return list of Chinese words in sentence. """
return jieba.lcut(sentence)
def get_chinese_character_positions(sentence):
"""Return a list of characters with their positions in the words. """
return [u'{}{}'.format(char, i)
for word in get_chinese_words(sentence)
for i, char in enumerate(word)]
Note that the above code is a very basic implementation to obtain a list of characters and words. You can do better by performing pre-processing such as grouping alphabets to English words, normalizing text, and removing stopwords, punctuations, and spaces.
Finally, the following code snippet shows how to train different Chinese word embeddings using Gensim.
from argparse import ArgumentParser
from gensim.models import Word2Vec
class SentenceGenerator(object):
def __init__(self, f, encoding='utf-8', mode='word'):
self.f = f # file-like object
self.encoding = encoding
self.mode = mode
def __iter__(self):
for line in f:
sentence = line.decode(self.encoding)
if self.mode == 'word':
# Return a list of words
yield get_chinese_words(sentence)
elif self.mode == 'char':
# Return a list of characters
yield get_chinese_characters(sentence)
elif self.mode == 'char_position':
# Return a list of char+positions.
yield get_chinese_character_position(sentence)
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--filename')
parser.add_argument('--encoding', default='utf-8')
parser.add_argument('--mode', default='word')
args = parser.parse_args()
with open(args.filename, 'rb') as f:
sentences = SentenceGenerator(f, args.encoding, args.mode)
model = Word2Vec(sentences, size=300) # Train model.
model.save('test_' +args.mode) # Save model.
Chinese Word Vectors in Action
In early tests of Chinese natural language processing at Primer, we trained those three types of word embeddings on more than 3 million simplified Chinese news articles published in June 2017 (10 GB). The training of the three embeddings took about two days (on a Mac with 16GB memory and 3.3 GHz Intel Core i7 processor). We set the vector dimension as 300 (same as the dimension in Facebook’s Chinese word vectors).
For comparison purposes, download Chinese word vectors published by Facebook — these word vectors use word embeddings and they are trained on Chinese Wikipedia, including both simplified and traditional Chinese.
Load the pre-trained word vectors.
from gensim.models import Word2Vec
# Word vectors
word_model = Word2Vec.load('wv_word')
char_model = Word2Vec.load('wv_char')
pos_model = Word2Vec.load('wv_char_position')
# Facebook's Chinese word vectors.
fb_model = KeyedVectors.load_word2vec_format('wiki.zh.vec')
Let’s look at some examples.
狗 + 小猫 – 猫 → ?
dog + kitten – cat → ?
# The most similar word with vector (狗 + 小猫 - 猫)
word_model.most_similar(positive=[u'狗', u'小猫'], negative=[u'猫'])
fb_model.most_similar(positive=[u'狗', u'小猫'], negative=[u'猫'])
In the function most_similar, the similarity between vector A and vector B is measured by cosine similarity:
cos(A,B)=∑i=1nAiBi∑i=1nAi2∑i=1nBi2cos(A, B) = \frac{\sum_{i=1}^n A_i B_i}{\sqrt{\sum_{i=1}^n A_i^2} \sqrt{\sum_{i=1}^n B_i^2}}
cos(A,B)=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
Using the trained word embeddings, you get 小狗 (puppy) as the most similar word. Not bad! Facebook’s fb_model returns 小脸 (little face). 小狗 (puppy) is ranked at the sixth position.
Could you get 小狗 (puppy) with character embeddings? In fact, with character embeddings, 狗 + 小猫 – 猫 (dog + kitten – cat) always equals 小狗 (puppy), because 狗 + 小 + 猫 – 猫 = 小 + 狗 is always true!
As 小狗 (puppy) includes two characters, it’s not in the char+position vocabulary. Instead of finding the most similar words, you could compare the vectors of 狗 + 小猫 – 猫 (dog + kitten – cat) and 小狗 (puppy) using cosine similarity:
from sklearn.metrics.pairwise import cosine_similarity
# cosine similarity between 狗 + 小猫 - 猫 and 小狗
cosine_similarity(pos_model.wv[u'狗0'] + pos_model.wv[u'小0'] +
pos_model.wv[u'猫1'] - pos_model.wv[u'猫0'],
pos_model.wv[u'小0'] + pos_model.wv[u'狗1'])
The cosine similarity is 0.64 — this means 狗 + 小猫 – 猫 (dog + kitten – cat) and 小狗 (puppy) have quite similar vectors.
Ok let’s look at another example:
皇帝 + 女人 – 男人 → ?
emperor (or king) + woman – man → ?
# the most similar word with (皇帝 + 女人 - 男人)
word_model.most_similar(positive=[u'皇帝', u'女人'], negative=[u'男人'])
fb_model.most_similar(positive=[u'皇帝', u'女人'], negative=[u'男人'])
Using Facebook’s word embeddings, the most similar word is 帝(emperor) which doesn’t look like a good result. Why don’t Facebook’s Chinese word vectors perform as expected? The possible reason is that these word vectors are trained on Chinese Wikipedia, which includes only 961,000 articles on Sep 10, 2017 (compared to 5,475,693 English Wikipedia pages).
Can you guess which word you get using the word_model? Not 皇后(queen) nor 女皇(empress). You get 武则天(Zetian Wu). This is a little surprising but does make sense, considering that when one says ‘empress’ in China, one usually means Zetian Wu, the only empress in Chinese history. Fair enough.
However, 皇帝 + 女人 – 男人 (emperor + woman – man) vector and 武则天(Zetian Wu) vector are not very similar using character embeddings and char+position embeddings. The reason is that characters 武(military), 则(then), and 天(day or sky) have very different meaning from the whole word 武则天. This often happens when the word is a named entity. Therefore, one way to improve character and char+position embeddings is to not separate named entities as characters [4].
# cosine similarity between 皇帝 + 女人 - 男人 and 武则天
cosine_similarity(char_model.wv[u'皇'] + char_model.wv[u'帝'] +
char_model.wv[u'女'] - char_model.wv[u'男'],
char_model.wv[u'武'] + char_model.wv[u'则'] + char_model.wv[u'天'])
# output score is 0.28
cosine_similarity(pos_model.wv[u'皇0'] + pos_model.wv[u'帝1'] +
pos_model.wv[u'女0'] - pos_model.wv[u'男0'],
pos_model.wv[u'武0'] + pos_model.wv[u'则1'] + pos_model.wv[u'天2'])
# output score is 0.26
The Bottom Line
What is the best strategy when choosing among one-hot encoding, character embedding, word embedding, and char+position embedding for Chinese NLP applications? When you have a large amount of data for training, one-hot encoding should perform well. However, it is rare that you will be swimming in training data. In the more typical data-sparse scenario, embeddings show their power. For example, if you encounter ‘smart’ but not ‘intelligent’ in training data, you still know how to handle ‘intelligent’.
Word embedding usually perform best in downstream NLP tasks. But in some cases, char+position embedding can do better: Peng and Dredze [3] showed that char+position embedding performs best in a Chinese social media named entity recognition task. Also, character embedding has been proved to be useful in a Chinese segmentation task [7]. Whichever you choose, pay close attention to the latest developments in multi-lingual natural language processing. This is a fast-changing field!
Reference
[1] Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. In arXiv preprint arXiv:1301.3781.
[2] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. In Empirical Methods in Natural Language Processing (EMNLP).
[3] Nanyun Peng and Mark Dredze. 2015. Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings. In Empirical Methods in Natural Language Processing (EMNLP).
[4] Xinxiong Chen, Lei Xu, Zhiyuan Liu, Maosong Sun, and Huanbo Luan. 2015. Joint learning of character and word embeddings. In International Joint Conference on Artificial Intelligence (IJCAI).
[5] Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2016. Enriching Word Vectors with Subword Information. In arXiv preprint arXiv:1607.04606.
[6] Wenzhe Pei, Tao Ge, and Baobao Chang. 2014. Max-Margin Tensor Neural Network for Chinese Word Segmentation. In Annual Meeting of the Association for Computational Linguistics (ACL).
[7] Xinchi Chen, Xipeng Qiu, Chenxi Zhu, Pengfei Liu, and Xuanjing Huang. 2015. Long Short-Term Memory Neural Networks for Chinese Word Segmentation. In Empirical Methods in Natural Language Processing (EMNLP).
Further Readings
- Overview of word vectors: The amazing power of word vectors
- Word2Vec algorithm: Word2Vec Tutorial – The Skip-Gram Model
- More advanced Chinese embeddings are discussed in: Improve Chinese Word Embeddings by Exploiting Internal Structure and Joint learning of character and word embeddings.
- A novel strategy to learn character embeddings by considering the visual appearance of Chinese characters: Glyph-aware Embedding of Chinese Characters
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



