Building Software for Any Infrastructure
A company’s data is often its most valuable asset. The modern enterprise relies on its data for performance monitoring, market insights, and for maintaining competitive advantages and institutional knowledge. However, with the explosive growth of data and data types, companies are faced with the increased challenge of organizing, managing, and gaining insights from their data. AI-based solutions used to address these challenges are on the forefront of machine learning, infrastructure design and deployments, and flexible computing.
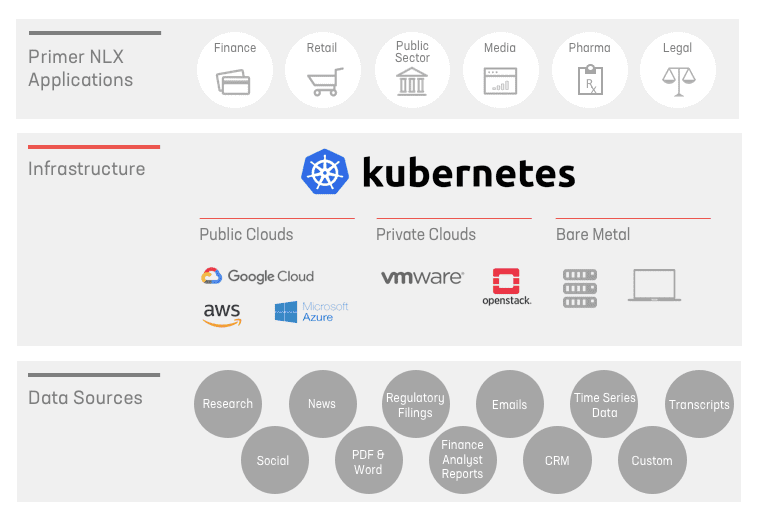
At Primer, we build machine learning systems that can read (NLP) and understand (NLU) diverse sets of unstructured text data, and provide users with a suite of summarized outputs (NLG) — from PDFs to knowledge bases. Our goal is to help companies accelerate their understanding of the world around them — from academic researchers, to financial analysts, to public sector employees.
In many of our deployments, our customers bring their data to our platform and we deploy our suite of AI engines on their infrastructure. This allows companies to keep their proprietary data secure within the confines of their own network. However, it introduces a unique set of challenges that we have to address. To frame the problem in common language: The objective is to extract meaning, better organize, and summarize terabytes to petabytes of unstructured data across a variety of cloud and on-premise deployments with cutting-edge and continually evolving AI-engines. Questions we consider include:
- How do we maintain product continuity across different infrastructures?
- What if the customer is running on an architecture we’ve never worked with before?
- Will our customers have enough computing resources on hand?
- What will it cost to support our customers within our hosted solution?
At the risk of reductionism, there are two broad strategies to follow. The first is to make the system requirements and installation process as generic as possible, making few assumptions about the customer’s infrastructure. And the second is to adopt bespoke “platforms” that are supported by the product and leverage what’s known about those platforms to automate the process.
Each strategic approach comes with trade-offs. The first is less work for your engineers but potentially brings friction for the customer and pre-sales teams. The second can yield a positive customer experience but can be costly to maintain—and when implemented poorly, the customer may have a negative experience in spite of the extra effort. The gravity of the trade-offs is compounded when the company is in its early stages and every engineer needs to be tied to critical functionally that can scale the business.
At Primer, we chose a hybrid of the two strategies and have invested in strategies and technologies to minimize our time to deploy and maintain solutions while also minimizing the amount of engineering cycles required to do so. We achieve this by leveraging Kubernetes as an orchestration technology. Kubernetes allows us to build for one notion of infrastructure instead of a bespoke set of approaches tied to specific configurations and operating systems. Traditionally when designing software, a considerable amount of debate occurs around how using AWS, GCP or perhaps Azure will change software design. Each of these cloud providers has non-trivial differences that can make an application dependent on that provider, especially if you take advantage of the more useful features of the provider. Instead of mitigating this by leveraging less of the cloud provider’s offerings, our approach allows our engineering teams to make more assumptions about the characteristics of the infrastructure. The big win for Primer is that Kubernetes does much of the heavy lifting of translating its design primitives to different infrastructure types. Ideally, this brings the best of both worlds: the ability to build software for a highly automated deployment/installation while still having the flexibility to adapt to almost any infrastructure our customers may use.
This idea is far from novel, and can be found in an increasing number of companies across a variety of verticals. We merely created an abstraction called an “interface” that allows us to handle many similar but different implementations of the same functionality. The novelty worth mentioning is that the hybrid approach both informs and enables great flexibility in future product design and iterative product improvements, whereas historic infrastructure considerations can come at the very end of the development cycle or constrain aspects of the final solution.
This freedom has enabled us at Primer to focus our precious engineering talent on more significant and more distinguishing matters. We can focus on rapidly tuning our engines with the latest algorithmic approaches, and we can now distance ourselves from the concerns of “what operating system” and “what cloud provider”.
As if the above benefits were not enough, using a solution like Kubernetes also enables Primer to take advantage of cost savings measures like AWS Spot Instances. Using Spot has traditionally been difficult because of the way we thought about infrastructure. Servers are carefully crafted to serve a particular purpose, contain non-redundant state, and take human time and energy to replace. These factors make behaviors like that of the Spot market particularly disruptive to an environment. On the contrary, Kubernetes is built around a notion of servers being ephemeral by nature and not containing any state that can’t be lost. This philosophical difference commonly referred to as “pets” vs. “cattle”, actually negates most of the “penalties” of the Spot market.
At Primer, we use a service called Spotinst that has already taken a lot of the complexity out of leveraging Spot instances and has a native connector for Kubernetes. With Spotinst we simply plug our Kubernetes cluster into it and suddenly save 60-70% of our AWS spend alongside with Pod-driven infrastructure autoscaling, meaning that we don’t need to fit our instances to our containers and Pod sizes. The beauty of this solution is that we achieved these savings without investing any additional engineering effort. This flips the traditional cost/benefit model on its head when looking at the cost saving for infrastructure. Spotinst has been an invaluable partner for making our infrastructure more useful and cost-effective.
Spotinst has also provided additional tooling and automation, like a dashboard to view our cluster’s pod allocation across the cluster. We can see what instance types are being most effectively used, and make more informed decisions about our scaling and capacity needs.
Finally, Spotinst will provide our customers with a solution to cost effectively scale up their own computing environments as they use heavy compute AI-based solutions like Primer to drive new insights into their organization.
We believe that companies will have a growing need for services like Primer to provide insights into their ever-growing volumes of internal and external data. While a number of AI-based solutions will be developed, we believe that these solution providers will not have the luxury to fall back on traditional SaaS models, and that architectures like the one we propose will provide flexibility for both developers, support the deployment and maintenance within customers IT organizations, and increase the time to value for the end users.
Primer Enterprise
Informed, defensible analysis
Primer Enterprise is a secure AI platform that helps analysts and mission teams across the Intelligence Community, Defense, and Civilian agencies analyze massive volumes of unstructured data. It transforms fragmented reports, proprietary data, and open-source information into structured, traceable insight that supports faster, defensible decision-making.

Primer Command
Real-time operational clarity
Primer Command is an AI-powered monitoring platform that helps mission teams keep track of narratives, track evolving topics, and detect emerging threats across global news and social media. It provides real-time visibility into the information environment so leaders can understand events as they unfold.



